¿Qué es MLOps?
Marc Ortega
07/02/2023
Dentro de todo proceso de machine learning hay un concepto que en los últimos años ha ido cobrando más importancia y es esencial para el correcto flujo de cualquier solución, MLOps.
Machine learning operations (MLOps) o DevOps para el aprendizaje automático es el conjunto de mejoras prácticas para que los equipos ejecuten los modelos de manera eficiente y automatizada. Estos procesos garantizan que un modelo funcione correctamente en producción, se pueda escalar para una gran base de usuarios y funcione con precisión.
Las necesidades de un modelo en producción se podrían resumir de la siguiente manera:
Los datos sobre los que se aplica el modelo pueden escalar en volumen por situaciones ajenas a este y dejar de ser compatibles con el proceso de producción ideado.
Aquellos modelos que necesitan cambios en los parámetros que los definen necesitan de una metodología de seguimiento.
Monitorear el comportamiento y los resultados de un modelo nos asegura mantener su calidad y detectar la necesidad de nuevos entrenamientos.
Detectar cambios en la naturaleza de los datos para que el modelo aprenda de ellos a medida que cambian.
Debugar un modelo se puede convertir en una tarea compleja con un flujo mal definido. Además debemos asegurarnos de que los cambios no afecten al resto de procesos que se ejecutan en producción.
Prevenir errores en el código antes de subir a producción, así como mantener un repositorio de calidad que permita a otros miembros del equipo usar y entender el código desarrollado.
Categorías principales en MLOps
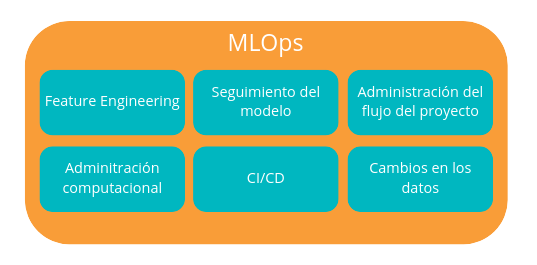
Entremos en mayor detalle sobre cada una de estas categorías:
- Feature Engineering es un término que aplica al conjunto de técnicas para facilitar la automatización de flujos ETL y la extracción de atributos de las variables para mejorar resultados y eficiencia.
- El seguimiento del modelo es básico para poder detectar cualquier cambio que pueda ocurrir en su comportamiento. Así como, detectar experimentos fallidos durante el entrenamiento de este. Un modelo de machine learning maduro es aquel que también puede capturar los hiperparámetros (pasados y actuales) y los KPI de calidad del sistema correspondientes.
- La administración del flujo del proyecto permite entender y controlar el flujo de datos entero, desde que se reciben hasta su transformación y posterior uso. En ese proceso se registran acciones que deben cumplirse en cada paso y genera errores en caso de cumplirse.
- La administración computacional tiene como objetivo gestionar óptimamente la escalabilidad de un proceso de machine learning. Algunos algoritmos requieren una gran cantidad de potencia computacional durante el entrenamiento y el reentrenamiento y poca durante la inferencia. Como a menudo estas dos tareas están conectadas por un circuito de control de retroalimentación, el sistema debe poder escalar hacia arriba y hacia abajo. A veces, se deben adjuntar recursos adicionales como GPU para el entrenamiento, mientras que no se requieren para la parte de inferencia. Los proveedores de nube pública abordan muy bien este problema ofreciendo escalado automático y balanceo de carga.
- El modelado CI/CD es muy similar al CI/CD del área DevOps, pero incluyendo verificaciones adicionales antes de la implementación del modelo.CI hace referencia al concepto de integración continua y CD entrega en contínuo. Estás metodologías imponen la automatización en la construcción, las pruebas y el despliegue de los modelos.
- La detección de cambios en los datos tiene como objetivo monitorear las características de los datos entrantes y el comportamiento del sistema. Cuando las características de los datos entrantes se desvían del rango esperado, se debe generar una alerta adecuada para que se pueda solicitar el reentrenamiento del modelo (automática o manualmente). Si esto no ayuda, la alerta debe escalarse y el equipo de desarrollo debe analizar más a fondo el problema.
En Datarmony, lo que pretendemos con este artículo es hacer una introducción simple a las implicaciones y beneficios de aplicar metodologías propias de DevOps a entornos de modelado de datos.