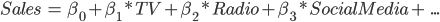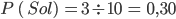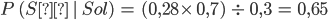Novedades de BigQuery
Daniel González
17/02/2023
En este post recopilamos y resumimos las principales novedades de BigQuery, recientemente anunciadas por Google.
El esfuerzo que la compañía está volcando en el desarrollo y mejora de sus servicios Cloud es una clara señal sobre la apuesta estratégica del gigante tecnológico, ahora que la publicidad online se ha visto seriamente amenazada por el fenómeno “cookieless”, y que su buscador ha visto el surgimiento de lo que parece ser un serio competidor.
Las nuevas capacidades y servicios de BigQuery están pensados para facilitar la migración al entorno Cloud de Google, y a hacer atractiva dicha migración mediante una oferta de valor que haga que el esfuerzo valga la pena.
Migration Service
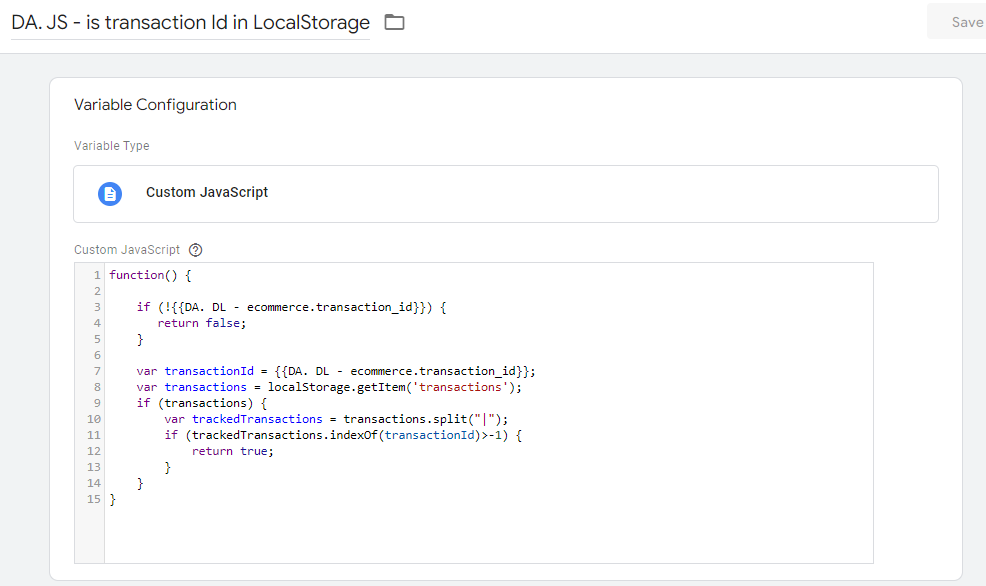
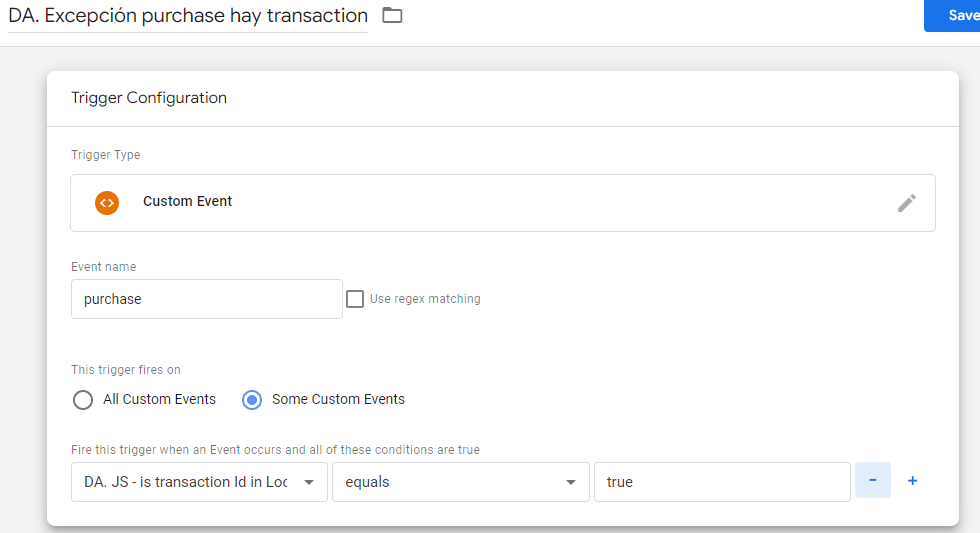
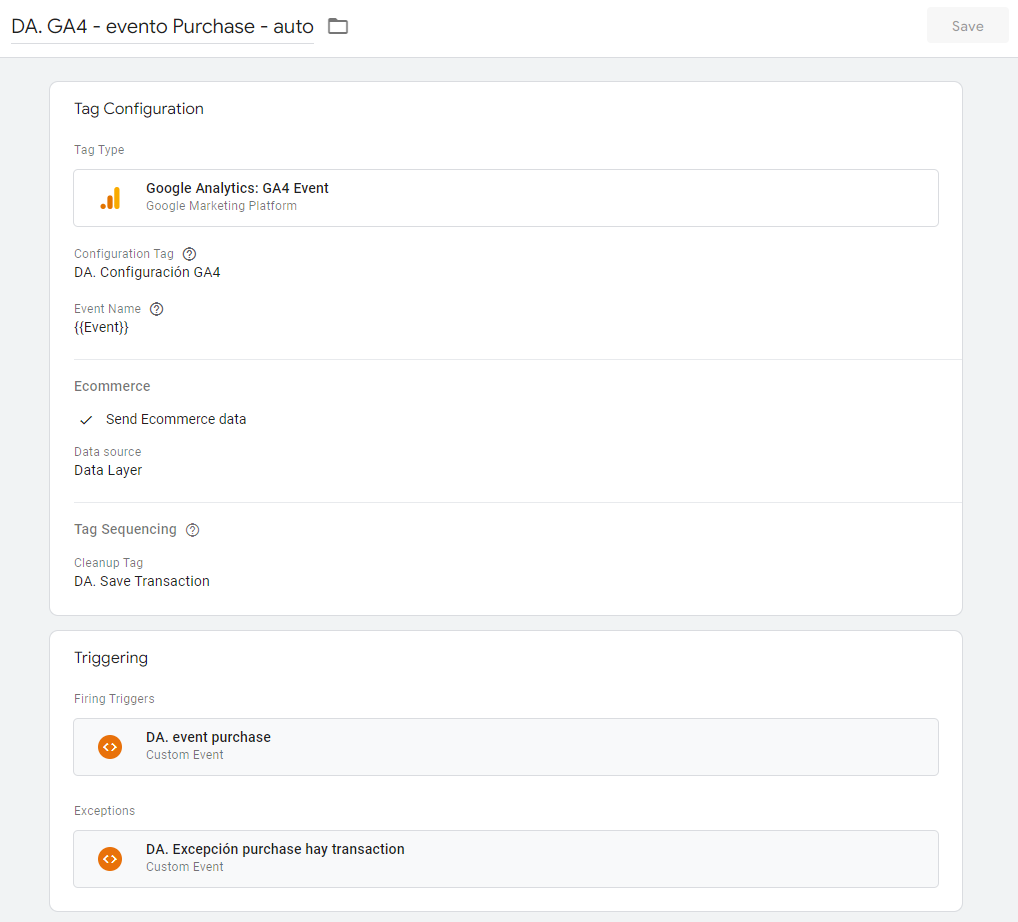
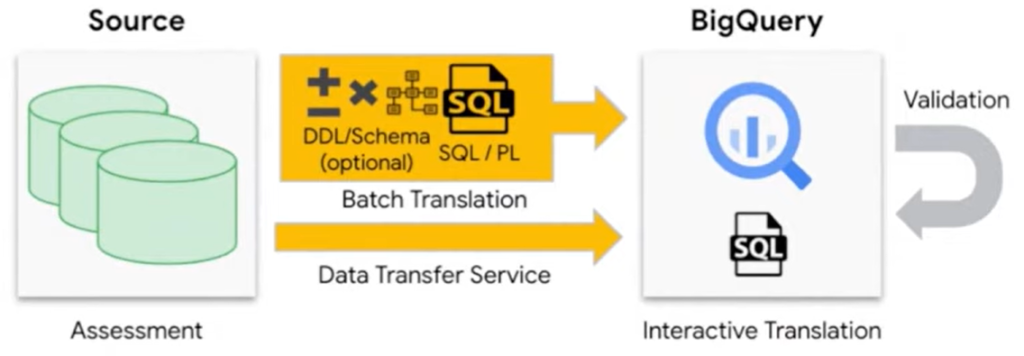
“El servicio de migración a BigQuery brinda herramientas que incluyen evaluación, traducción, transferencia de datos y validación, para una transición sin problemas y sin riesgos.
Además, a través de la adquisición de Compiler Works el año pasado, Google ha ampliado el soporte a 12 fuentes adicionales, incluyendo Oracle, Ateza, Vertica y Snowflake”.
(Google Cloud Tech, 2022b)
Uno de los aspectos más difíciles en cualquier migración es la modernización de la lógica de negocios de legado, como las consultas SQL, los scripts y los procedimientos almacenados. BigQuery Migration Service proporciona traducciones rápidas, correctas y legibles por humanos del código de legado, sin necesidad de dependencias en tiempo de ejecución. Además, estas traducciones se pueden ejecutar en modo por lotes o de manera puntual directamente desde el espacio de trabajo SQL.
Connected Sheets
Connected Sheets es una herramienta que permite analizar, visualizar y compartir datos de BigQuery directamente desde su hoja de cálculo.
Ya no es necesario preocuparse por ejecutar consultas manualmente. La herramienta crea y ejecuta las consultas, ya sea bajo demanda o según un horario previamente definido. Los resultados de las consultas se guardan en la hoja de cálculo para su análisis y compartición. Además, tanto si se desea comenzar los análisis directamente en Sheets como si se prefiere escribir una consulta en el editor SQL de Google Cloud, Connected Sheets ofrece la flexibilidad que necesita.
Anteriormente, Connected Sheets solo estaba disponible para los usuarios del plan de precios de Google Workspace Enterprise, pero Google ha anunciado que ahora está disponible para todos los usuarios de Sheets, incluido el plan personal gratuito.
Log Analytics
BigQuery está expandiendo su alcance más allá de los casos de uso de almacenamiento de datos tradicionales. Uno de estos nuevos casos de uso es el análisis de registros, donde se ingieren datos de dispositivos o aplicaciones y se llevan a BigQuery para su análisis.
Para mejorar el soporte a estos tipos de aplicaciones, Google ha agregado tres nuevas capacidades que ya están disponibles para el público en general. La primera es un nuevo tipo de datos JSON nativo que admite la descomposición de documentos semiestructurados en un formato de almacenamiento de columnas. Esto ofrece un mejor rendimiento y una mejor compresión de almacenamiento en comparación con el uso de un tipo de cadena estándar.
En segundo lugar, los índices de búsqueda permiten ejecutar consultas «aguja en un pajar» en los datos de BigQuery. Estos índices aceleran la velocidad con la que se pueden identificar las filas que contienen patrones específicos de texto. Hay un pequeño costo por el almacenamiento del índice, pero la mejora en rendimiento es notable.
Por último, la API de escritura de almacenamiento de BigQuery permite al motor de altas prestaciones manejar millones de operaciones por segundo sin degradar el rendimiento de las consultas.
Estas nuevas características pueden usarse de forma independiente, pero juntas se combinan para construir soluciones poderosas de análisis de registrar.
Dataform
Dataform es un servicio revolucionario para la creación de tuberías de transformación de datos escalables.
Dataform utiliza un lenguaje basado en SQL llamado SQL X para definir y administrar las tuberías de datos, lo que le permite preparar y transformar los datos con una gran eficiencia para su uso en inteligencia empresarial y análisis. Además, también es compatible con la preparación de datos para el aprendizaje automático y para sistemas secundarios.
Para asegurar una colaboración efectiva y un seguimiento de las mejores prácticas en el desarrollo de software, Dataform trata las tuberías como código y las administra mediante versiones en repositorios Git, como GitHub o GitLab.
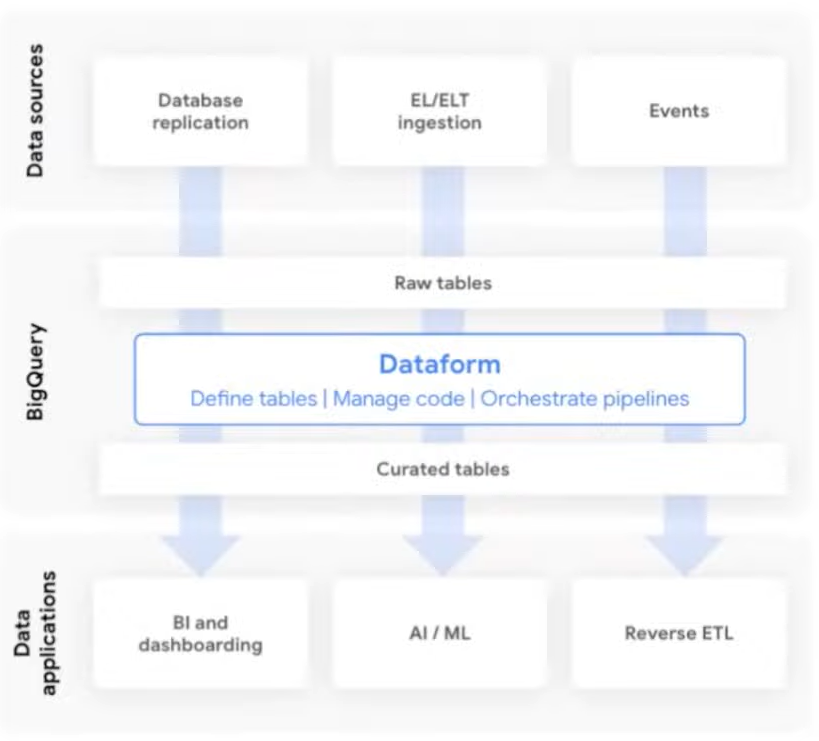
Google ha anunciado que Dataform está disponible en versión preliminar, y lo mejor de todo es que no hay ningún cargo adicional por el uso de Dataform, solo los costos de ejecución y almacenamiento de consultas en BigQuery.
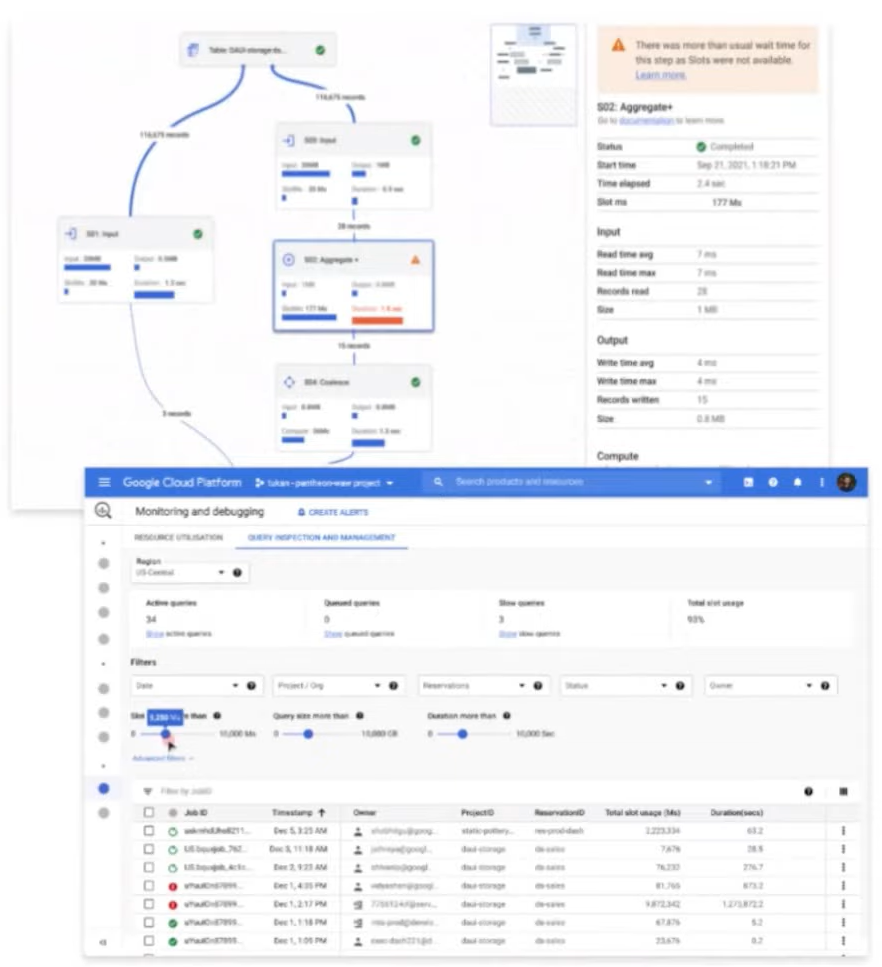
Query Inspector
Bigquery ofrecía detalles sobre la ejecución de consultas a través de sus tablas de esquema de información, pero esta información a veces resultaba difícil de descifrar.
Por eso, Google ha lanzado en versión preview de Query Inspector, una nueva herramienta que brinda visualizaciones adicionales para depurar el rendimiento de las consultas, incluyendo un gráfico de ejecución de consultas.
Bigquery descompone la consulta en varios estadios, muchos de los cuales funcionan en paralelo, y el gráfico de consultas ayuda a comprender el flujo de datos a través de estos estadios y a identificar los cuellos de botella. Query Inspector también incluye un solo lugar para ver y comparar el rendimiento de las consultas, permitiéndote profundizar en acciones específicas.
En 2018, Bigquery fue el primer almacén de datos en la nube en ofrecer integración con aprendizaje automático. Bigquery ML permite entrenar, ejecutar y desplegar modelos de aprendizaje automático en Bigquery mediante consultas SQL estándar. Con Bigquery ML, no es necesario preocuparse por la gestión de la infraestructura de aprendizaje automático o la seguridad de los datos, ya que, al igual que el resto de Bigquery, es totalmente automatizado y sin servidor.
Google ha intgrado Bigquery ML en el registro de modelos de AI de Vertex. El registro de modelos es un repositorio central donde se pueden gestionar los ciclos de vida de los modelos de aprendizaje automático. Con solo unas pocas líneas de SQL, se pueden registrar los modelos de Bigquery ML en el registro de modelos para versionar, evaluar o desplegar para predecir en línea.
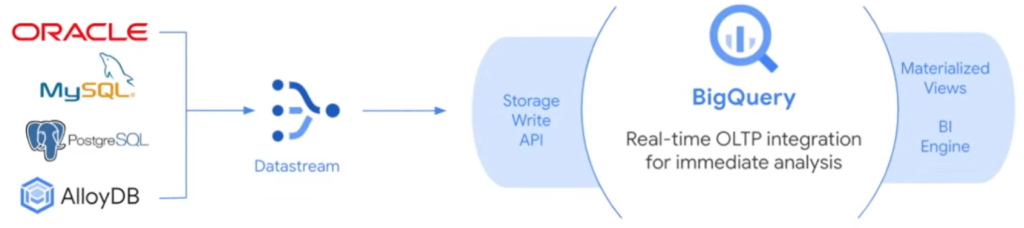
DataStream
El año pasado Google lanzó DataStream, un servicio de captura y replicación de cambios fácil de usar y sin servidores. Al integrar DataStream con BigQuery, ahora se puede analizar eventos comerciales en tiempo real desde sus sistemas operativos. DataStream replica automáticamente tanto el esquema como los datos de los registros de las bases de datos de origen en BigQuery. A partir de ahí, se puede ejecutar tuberías de transformación o utilizar características de BigQuery como vistas materializadas.
Google ha lanzado, en preestreno, una nueva integración incorporada entre DataStream y BigQuery. Con esta nueva integración, DataStream replica directamente en BigQuery a través de su interfaz de transmisión de altas prestaciones y no es necesario utilizar servicios adicionales. DataStream incluye soporte para Oracle y MySQL. Además han lanzado una vista previa para Postgres, incluyendo Amazon Aurora y el nuevo servicio de base de datos compatible con Postgres de Google, AlloyDB.
Object Tables
Aunque BigQuery se ha centrado hasta ahora en datos estructurados como enteros y cadenas, así como datos semi-estructurados como JSON, se dan cuenta de que hay una gran cantidad de insights que se pueden obtener de los datos no estructurados como imágenes, video, audio y texto. Por eso, están presentando la vista previa de las tablas de objetos de BigQuery.
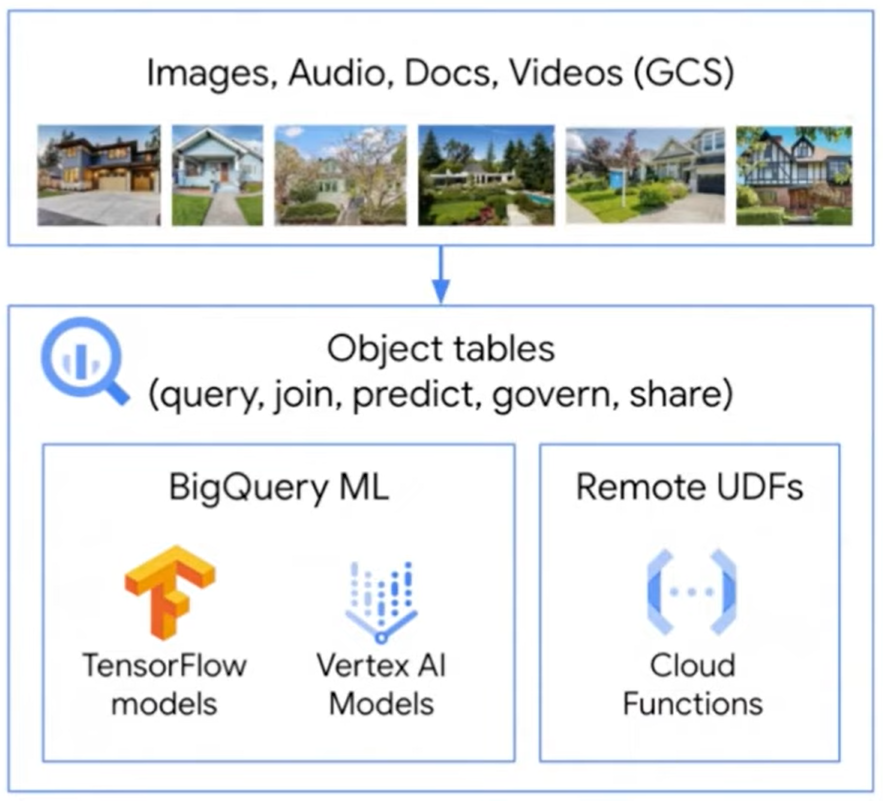
Estas tablas proporcionan una representación tabular de los objetos en el almacenamiento de Google Cloud y permiten un acceso completo a SQL en los metadatos del objeto. También permite a los usuarios utilizar modelos de aprendizaje automático incorporados en BigQuery, y crear políticas de acceso fino para asegurar los datos del objeto de la misma manera que lo haría en otras tablas de BigQuery.
Con estas novedades y mejoras, BigQuery ayuda a los clientes a sacar el máximo provecho de sus datos, ya sea estructurados o no estructurados, para poder tomar decisiones informadas y mejorar su negocio. Con la integración de BigQuery ML, la posibilidad de versionar, evaluar y desplegar modelos de aprendizaje automático, los clientes pueden aprovechar al máximo el poder de la inteligencia artificial. Aparte, con DataStream, los clientes logran analizar eventos comerciales en tiempo real y con la nueva integración directa con BigQuery, pueden replicar sus datos de manera rápida y eficiente.
Las tablas de objetos de BigQuery también permiten a los clientes acceder a metadatos y utilizar modelos de aprendizaje automático para obtener insights valiosos de datos no estructurados
En resumen, BigQuery es un almacén de datos escalable, sin servidores y de bajo costo diseñado para la agilidad empresarial. Con su integración con BigQuery ML, la posibilidad de analizar datos en tiempo real con DataStream y la accesibilidad a datos no estructurados con tablas de objetos, BigQuery ayuda a los clientes a obtener insights valiosos de sus datos para mejorar su negocio. Con un enfoque en la apertura, la integración y la inteligencia, BigQuery es una herramienta clave en la transformación digital de las empresas.
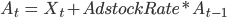
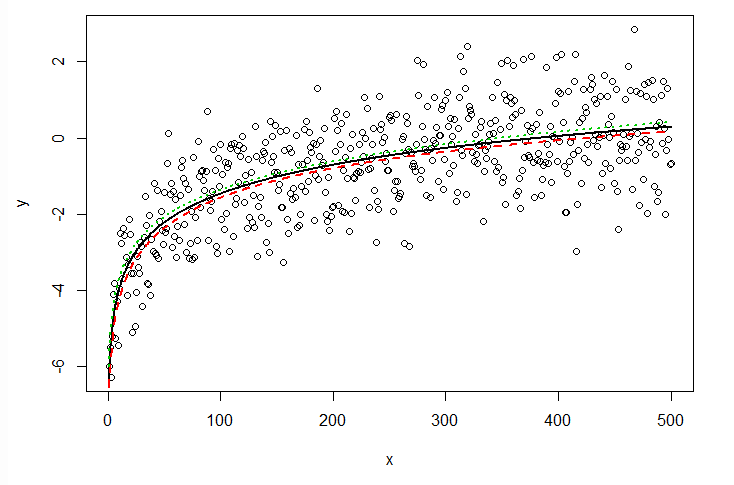
 para saber qué canal tuvo más impacto en las ventas. Básicamente, los estimadores nos indican cuánto aumentan las ventas si aumentamos en una unidad la inversión de cada canal.
para saber qué canal tuvo más impacto en las ventas. Básicamente, los estimadores nos indican cuánto aumentan las ventas si aumentamos en una unidad la inversión de cada canal.