Aprendizaje Supervisado en Machine Learning
Camila Larrosa
02/02/2023
Bienvenidos a otro artículo de la serie Machine Learning realizado por nosotros en Datarmony, con el objetivo de compartir las matemáticas que se utilizan detrás del concepto de inteligencia artificial, en nuestro día a día como científicos de datos.
Después de hablar sobre el aprendizaje automático y saber que se puede clasificar en tres tipos de aprendizaje machine learning: aprendizaje supervisado, no supervisado y de refuerzo. En esta publicación profundizaremos en el primer grupo.
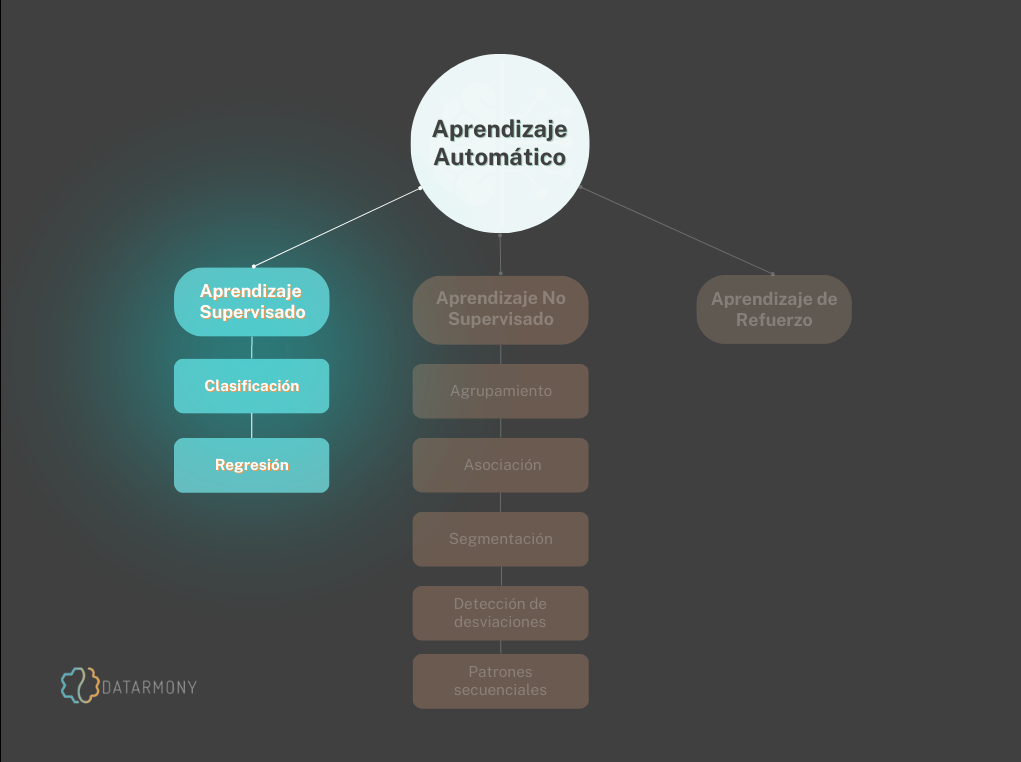
El aprendizaje supervisado es una tarea de aprendizaje automático donde el algoritmo aprende de datos con pares de ejemplos de entradas-salidas, es decir, el modelo aprende a realizar una tarea a partir de ejemplos etiquetados, que se le enseñan en la fase de entrenamiento.
Cuando se trata de aprendizaje supervisado, primero debemos recordar que el conjunto de datos utilizado para entrenar el algoritmo de Machine Learning estará compuesto por variables de características (también llamadas de features), que estarán rotuladas por una variable objetivo (o target).
En este enfoque, el modelo aprende a realizar una tarea a partir de ejemplos etiquetados, que se le enseñan en la fase de entrenamiento. Pero, ¿qué subcategoría de algoritmo elegir?
¿Algoritmos de Clasificación o algoritmos de regresión?
Los algoritmos de aprendizaje supervisado se sub categorizan en dos grupos: Clasificación y Regresión. La diferencia entre ellos está en el tipo de resultado que queremos que produzca la técnica de aprendizaje automático. Veamos la diferencia.
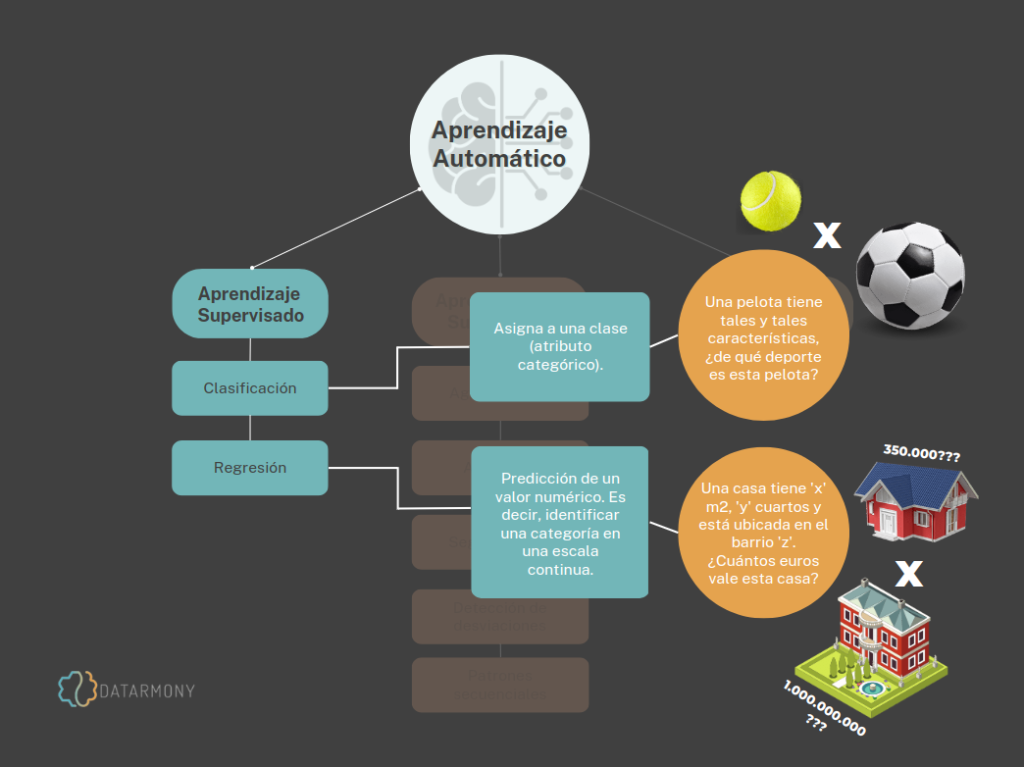
En la clasificación, el objetivo es identificar a qué categoría pertenece una determinada muestra del problema, entre un número limitado de categorías. Si un correo electrónico es SPAM o no; si el riesgo de otorgar crédito a un cliente es bajo, moderado o alto; si un mensaje tiene un sentimiento positivo, negativo o neutral; qué personajes de dibujos animados aparecen en una determinada imagen, etc.
A diferencia de la clasificación, el aprendizaje supervisado de regresión, la idea es predecir un valor numérico; o en otros términos: identificar una categoría en una escala continua. En este caso, el algoritmo aprende de los datos y los modela en una función para hacer predicciones. Este tipo de algoritmos se pueden utilizar, por ejemplo, para predecir el precio de un inmueble, el número de transacciones y el valor de compra que realizará un cliente en el próximo mes, calcular el vida útil de una máquina, cuántas uvas se recogerán en una cosecha, o cualquier otra cantidad cuantitativa.
Además, es importante señalar que lo que diferencia si un problema es del tipo clasificación o regresión, no es una simple distinción entre la predicción de un número, o una letra/palabra, ya que podemos, por ejemplo, predecir valores numéricos en la clasificación de problemas. Sin embargo, en estos casos, esta predicción significa siempre una categoría.
Es decir, en la clasificación, un número siempre significa una clase, que podrá ser reemplazada por cualquier letra, palabra o incluso por otro número, sin perjuicio de la comprensión de las predicciones. Incluso, en la práctica, es muy común utilizar la clasificación binaria con los números 0 y 1 para representar las clases.
Principales algoritmos de aprendizaje supervisado utilizados en la Clasificación y en la Regresión
Hay varias técnicas de Machine Learning que podemos utilizar en problemas de clasificación y de Regresión. Ejemplos de aprendizaje supervisado:
Clasificación: Naive Bayes, Máquinas de Vectores de Soporte (Support Vector Machines, SVM), Regresión Logística, Árboles de Decisión, Bosques Aleatorios y Redes Neuronales.
Regresión: Regresión Lineal, Regresión no Lineal, Máquinas de Vectores de Soporte (SVM), Árboles de Decisión, Bosques Aleatorios y Redes Neuronales.
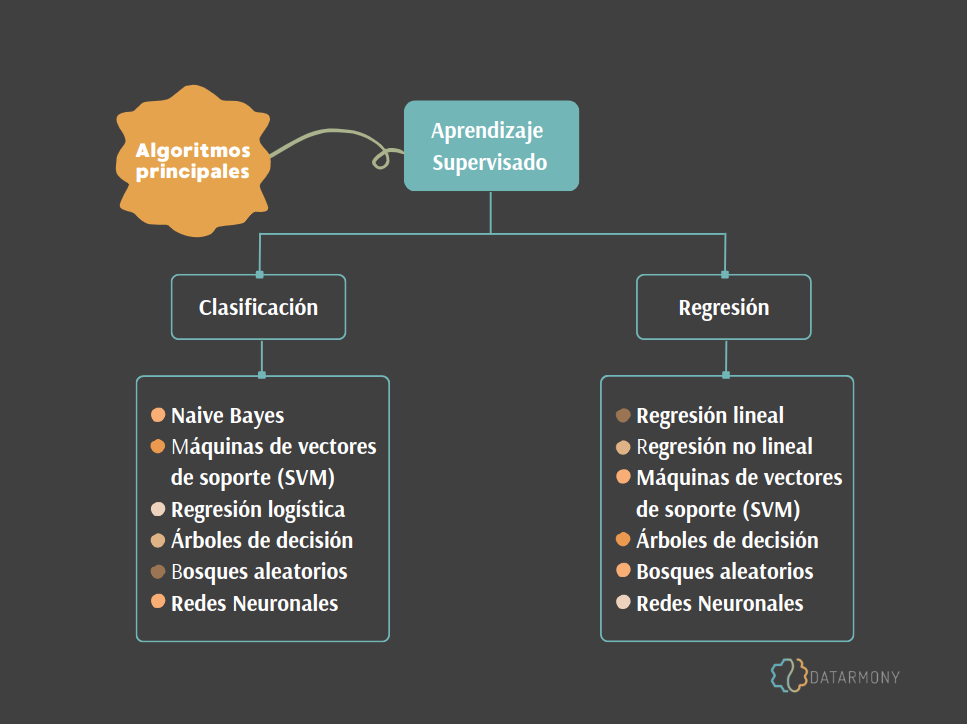
Es posible que hayas notado que muchas de las técnicas no se limitan solo a la clasificación o solo a la regresión, algunas funcionan para ambos problemas.
Otro motivo de confusión frecuente, interesante de señalar, es la técnica de regresión logística. Por su nombre, nos lleva a pensar que se trata de una técnica de regresión, pero en realidad es una técnica utilizada únicamente para problemas de clasificación.
Consideraciones finales
Esperamos que después de este artículo no queden dudas sobre los tipos de aprendizaje supervisado, la diferencia entre técnicas de clasificación y regresión, y por qué elegir una o otra a la hora de resolver un problema de Machine Learning.
En los próximos artículos seguiremos hablando de las técnicas de aprendizaje supervisado, acercándonos técnica a técnica. Si quieres aprender, por ejemplo, cómo usar algoritmos de Árboles de decisión para problemas de clasificación o regresión, y cómo es su diferencia en la práctica, sigue leyendo nuestros posts.