Tealium es un ecosistema de productos que en su conjunto componen el Tealium Customer Data Hub o la Customer Data Platform, Tealium CDP; ambos términos son igualmente utilizados para referirse a una infraestructura encargada de recoger, procesar, enriquecer y activar los datos provenientes de prácticamente cualquier fuente de datos.
Novedades en Tealium
Estamos viendo como Tealium está incluyendo, por pequeñas que sean, nuevas funcionalidades y mejoras cada vez más rápido, así que vamos a echar un vistazo a las novedades de este noviembre, que encontraréis en la comunidad de Tealium, donde publican la mayoría de novedades, pero también hay muchísima información en la Tealium Documentation, donde se detallan muchos temas como Tealium GDPR, Tealium cookies, Tealium Functions y Tealium Web Companion (como el resto de aplicaciones de la extensión Tealium Tools). Los puntos a comentar pertenecen a Tealium iQ y Tealium AudienceStream.
Tealium y el cliente
En el lado cliente tenemos una actualización de la etiqueta de AT Internet Piano Analytics, que mejora la carga asíncrona, añade nuevas funcionalidades de depuración y hace una limpieza de las categorías de mapeo de variables.
Tealium entre el cliente y el servidor
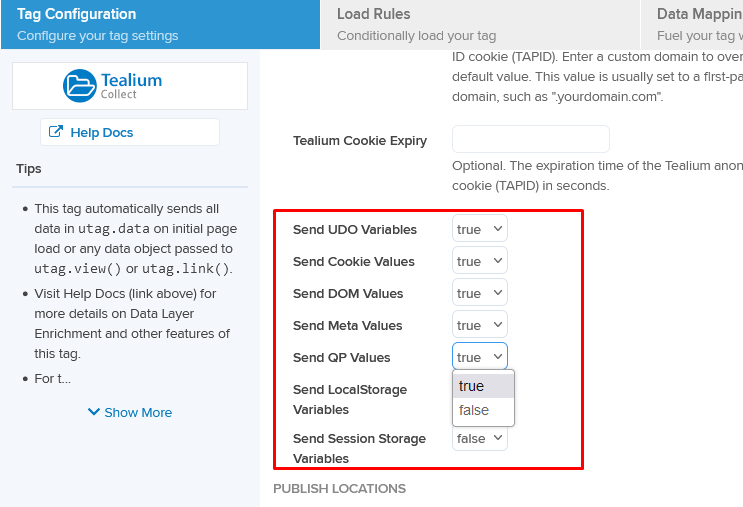
Algo entre el cliente y el servidor es la actualización de la Tealium Collect tag, que nos permite enviar información a los productos del lado servidor, como EventStream. Esta incluye varias nuevas opciones en la sección de configuración, con las que puedes escoger por separado qué tipos de datos quieres enviar al servidor: cookies, LocalStorage, SessionStorage, parámetros de la URL, variables UDO, y valores meta, lo cual nos ayudará en reducir el tamaño de la petición a enviar y en construir una implementación más limpia.
En resumen, con un par de funcionalidades, tags y conectores nuevas, y algún fix, no estamos ante una release que marque un antes y un después, pero sí nos asegura que Tealium sigue mejorando y ampliando con Tealium IQ, como sus productos server-side.
Por último, me gustaría aprovechar el estar comentando estas novedades para recomendar a cualquier persona interesada en mejorar el ecosistema Tealium y tenga alguna idea, el enviar una sugerencia a través de su nuevo portal.
Los bots en web también conocido como robots o rastreadores son software que escudriñan las páginas de las webs con varios objetivos, como pueden ser el indexar contenido en tu web para atraer clientes y subir peldaños en el posicionamiento de los navegadores, al estar su página referenciada desde muchas otras.
¿Cómo eligen los bots qué webs analizar?
Su patrón se basa en que a partir de un listado de urls de distintas webs conocidas, las van analizando y guardando los enlaces que encuentran para añadirlas a su listado. De esta forma si tu sitio web está siendo referenciada por otra que un bot está analizando, dará con la url de la referencia y se la guardará para posteriormente analizar tu web, mandarte mensajes si encuentra un formulario de correo, escribir comentarios en ella… por los motivos anteriormente dichos.
¿Cómo me protejo de los bots?
La manera más usada de protegerse ante bots es usar alguna clase de captcha. ¿Qué es un captcha? Para quien no los recuerde o no los hayan visto, son esas imágenes con letras garabateadas y difíciles de leer para demostrar que eras un humano.
Vale, si ahora lo recuerdas te estarás preguntando qué pasó con ellos, por qué no se usan ya… la respuesta es que a mucha gente le costaba bastante pasar esa barrera de seguridad o no quería pasarla directamente por lo que google desarrolló su versión llamada reCaptcha.
Versiones de reCaptcha
La primera versión de reCaptcha validaba que eras humano partir de palabras de proyectos de escaneo de textos que los ordenadores no podían identificar, ayudando de paso a estos.
La segunda versión, que creo que es la que todos mejor recordamos, era aquella donde te ponían una serie de imágenes y tenías que seleccionar las que tuvieran un coche, una moto… o una sola imagen donde tuvieras que clicar una parte, como la famosa del semáforo que hoy en día seguro que confunde a los nuevos usuarios de internet intentando averiguar si hay que seleccionar toda la estructura del semáforo o solo aquella que contiene las luces.
Por último y la más interesante, la tercera versión de recaptcha la cual por así decirlo es invisible. Se trata de algoritmos internos que comprueban si eres un humano a partir de unas migas de pan que dejamos los humanos como puede ser por las cookies activas, la IP, como te has desplazado hasta el botón que quieres pulsar… y en base a los datos que ha recogido te puntúa del 0 al 1, siendo 0 la detección de un bot y un 1 la de un humano. Normalmente y por consejo de Google los desarrolladores establecen que si no tienes una puntuación mínima de 0.7 se te trate como un bot.
¿Qué versión se debería de utilizar?
No recomendaría la primera versión porque ya está bastante obsoleta y resulta algo tediosa para los usuarios, ni tampoco la segunda versión que ya empieza a no ser eficaz ,ni siquiera al 80%, ya que gracias al avance en el software de estos bots ya son capaces de vez en cuando de identificar algunas imágenes para pasar la seguridad.
Respecto a la tercera versión, gracias a unas pruebas que hemos hecho durante un largo periodo de tiempo sabemos que hemos tenido 293 comprobaciones, de las cuales ningún bot ha conseguido pasar la seguridad de esta versión y como comentamos anteriormente no implica ningún esfuerzo por parte del usuario.
¿Todos los bots son malos?
No todos los robots son malos, hay algunos como el robot de google “Googlebot” que se encarga de analizar las webs tanto en su versión para escritorios y móviles.
Normalmente estos bots son respetuosos, pero si no quieres que rastreen tu sitio web basta con indicarlo en el archivo robots.txt y/o en la página en concreto que no quieres que analice con la regla noindex que se establece a con una etiqueta <meta> o un encabezado de respuesta HTTP.
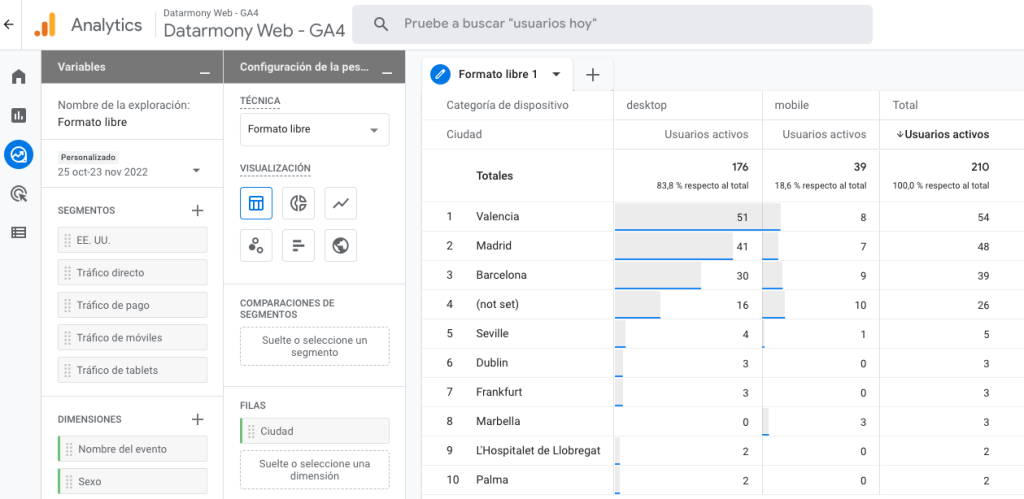
Con la llegada de GA4 hemos tenido que actualizar conceptos de medición y entender la nueva interfaz de presentación de los datos. Y en esta nueva interfaz, muy probablemente, no hemos encontrado los datos a los que estamos acostumbrados en Google Analytics Universal, lo cual nos ha empujado a trabajar con los informes de exploración.
Visualización de informes de exploración. Google Analytics 4
Los informes de exploración ofrecen múltiples posibilidades para visualizar nuestros datos. Hay que tener cuidado con mezclar las métricas y dimensiones correctas, pero gracias a ellos podemos obtener informes muy completos.
Cuando empezamos a trabajar con un informe de exploración lo primero que tenemos que hacer es importar nuestras dimensiones y métricas de entre todo el conjunto disponible, y aquí es cuando nos damos cuenta de que, en GA4, algunos nombres y datos son algo diferentes a lo que veíamos en Universal.
Transactions y purchases
Al querer obtener las transacciones o compras realizadas en un sitio o App, nos encontramos con que en GA4 tenemos esta información separada: podemos sacar el número de compras o purchases y el número de transacciones, y aquí debemos tener claro qué es cada cosa para validar nuestros datos y nuestra implementación.
Si estamos midiendo un ecommerce, en el que la única transacción viene con la compra de un producto, es de esperar que el valor de purchase y de transaction sea el mismo, pero hay que tener en cuenta que purchase hace referencia al evento “purchase” que se lanza a Google Analytics, con lo que podría darse el caso que quisiéramos lanzar este evento para identificar una acción del usuario diferente a una compra. Cuesta encontrar una razón para esto, más ahora que GA4 permite configurar cualquier evento como conversión, pero todo es posible.
Lo importante es que en el caso de un ecommerce, como decía, estos datos deberían tener el mismo valor.
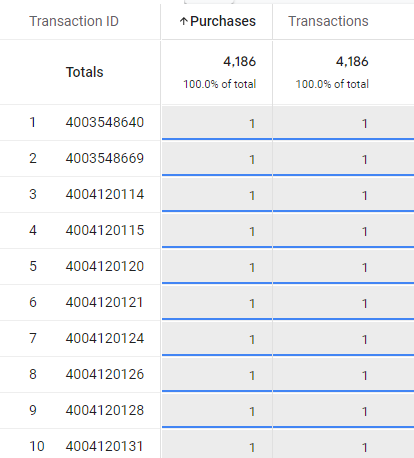
Tabla 1. Detalle de informe de transacciones. Implementación correcta
Además, en este caso vemos que cada Transaction ID es único, por lo que sabemos que no se están duplicando transacciones.
Problemas de implementación
Gracias a estos informes, podemos, con un vistazo rápido, determinar si hay problemas en la implementación.
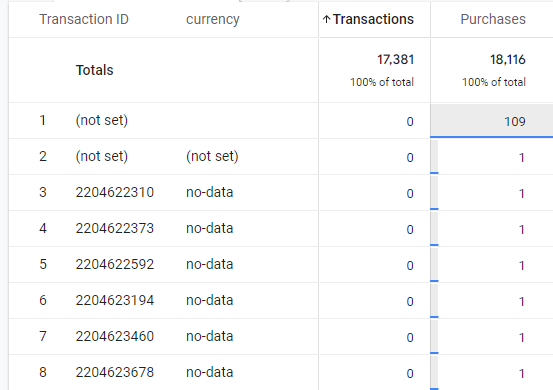
Tabla 2. Detalle de informe de transacciones. Problemas de implementación
Si nuestro informe fuera como el de la tabla 2, con datos diferentes en cada métrica, el caos está servido: no solo no tenemos las mismas transacciones y purchases, además nuestras transacciones se están lanzando varias veces.
Para ver una de las posibles causas basta con cambiar el orden de la tabla, de menor a mayor:
Tabla 3 Detalle de informe de transacciones. Not Set
No hay que enviar un evento purchasesin informar el identificador de la transacción
Un caso como el de la tabla 3 indicaría que nuestra implementación no es correcta: se está mandando eventos purchase de ga4 con el dato del identificador de la transacción sin informar (not set), por eso GA4 no lo interpreta como una transacción.
Hay que revisar la implementación y hablar con el departamento de IT para incluir el ID de transacción cuando corresponda.
La moneda ahora es importante: GA4 descarta la transacción si no se informa de la moneda.
En la segunda fila de la tabla 3, por ejemplo, sí tenemos el identificador de la transacción, pero el informe nos dice que no hay transacción.
Aquí el problema es la dimensión “currency”: GA4 descarta la transacción si no se informa de la moneda.
Detalle de informe de transacciones 4. No hay datos sobre el tipo de moneda, y la transacción no se registra
Esto es fácil que ocurra en implementaciones heredadas de Universal, donde no era obligatorio informar de la moneda. Si montamos etiquetas de purchase para GA4 con un DataLayer desarrollado originalmente para Universal, tendremos que asegurarnos de que la moneda se informa correctamente. Si no es así, contacte con el departamento de IT para que incluyan esa información.
Las transacciones duplicadas: un tema complejo que da para otro post
El último de los problemas que se observa en la tabla 2 es el de las transacciones duplicadas en GA4. Para solucionarlo, tendremos que habilitar una cookie para almacenar el identificador de la transacción, de forma similar a lo que se hacía para resolver el tema en Universal.
Calculas el retorno de tu inversión ROI pero ¿y el ROD de tus datos?
Enric Quintero
07/12/2022
Muchas son las voces que últimamente se levantan en contra de la apología por el dato.
Y no refiero a colectivos como los terraplanistas que tristemente hacen gala de su ignorancia, sino a profesionales que tras múltiples promesas sobre la bondad de los datos no ven resultados palpables.
¿Realmente los datos están sobrevalorados?
“Llevo años invirtiendo en tecnología de datos y no veo valor” Anónimo
Frases como la anterior surgen de profesionales que tras años de estar convencidos sobre la apuesta por los datos, quedan exhaustos al no poder demostrar avances significativos.
Implementaciones de herramientas de explotación de datos, integraciones de sistemas de agregación de información, inclusiones de soluciones de depuración de data, y un largo etcétera a nivel tecnología, no nos deja pensar en el verdadero problema, sólo recibimos el siguiente mensaje: “es que lo tienes que tener”.
¿Qué está fallando?
Los datos son una herramienta, no un fin por sí mismos.
Salir del consumismo de tecnología a la que nos empujan, solo se consigue reflexionando sobre la verdadera función de los datos, que no es otra que la de cualquier herramienta. Como tal, los datos deben cumplir un propósito, que no es tener la tecnología en sí, es conseguir un objetivo bien definido gracias a la misma.
Esta reflexión de lo más sencilla, no se concreta bien ni antes ni después de integrar una solución ¿quién se atreve a decir que la inversión que se ha hecho y, tras 8 meses de duro trabajo, no ha obtenido nada de lo definido a priori? Mejor salir silbando….
Y es que el gran error es empezar por la tecnología, en vez de definir la necesidad. Es como salir corriendo a pillar un taxi sin saber a dónde vas.
Por tanto, la primera conclusión para evitar frustración con los datos sería: define, cuánto más en detalle mejor, qué quieres conseguir gracias a los datos, y a partir de ahí decide qué tecnología te ayudará con ello, nunca al revés.
¿Ya lo tenemos todo? No, faltaría cuantificar el impacto de lo conseguido.
Return on Data (ROD)
Fundamental en cualquier acción, es medir en qué grado se ha conseguido lo que se pretende y, comparar el beneficio obtenido versus el coste que ha supuesto.
Este proceso está ampliamente extendido en el ámbito de los negocios y del marketing, siendo el retorno de la inversión (ROI) o el retorno de la inversión publicitaria (ROAS) indicadores muy utilizados y populares.
Que no se calcule o que incluso se desconozca el retorno de la inversión en data (ROD), viene a confirmar la problemática planteada en este post. ¿Cómo quieres saber el impacto de lo que haces en data si no lo mides?
¿Cómo calculamos el Return on Data (ROD)?
Para calcular el ROD seguiremos el mismo cálculo que se utiliza para obtener el ROI, pero en este caso usaremos “las ganancias gracias a los datos” menos el “coste de la data”, todo dividido por “el coste de la data”.
ROD= ((Ganancias por la Data – Coste inversión en Data)/ Coste inversión en Data)
El porcentaje obtenido puede ser global para todas las actividades que conlleven data, o incluso podemos calcular un ROD para cada actividad de data y compararlos.
Aquí podemos entender como “coste de la inversión en data” como los costes de infraestructura, costes de mantenimiento y costes de explotación (tanto soft, hardware y talento).
Por otro lado, los beneficios gracias a la data los podemos identificar como:
Impacto directo en negocio (aumento de clientes, de ventas, de margen, etc).
Cabe decidir que para ello seguramente tendremos que lanzar un test A/B.
En conclusión, reflexionar sobre lo que se necesita, activar acciones basadas en datos para conseguirlo y medir en qué grado se ha logrado es la clave para saber si tus datos te están ayudando.
Pero, ¿estás de acuerdo? ¿Has usado alguna vez el ROD? ¿Te parece de utilidad?
Please, comparte tus experiencias y así le daremos más valor a este post 😀
En un post anterior ya tratamos el tema de la optimización del clima laboral a través del análisis de redes. En ese artículo, decíamos que hoy en día los empleados no sólo buscan un salario competitivo, si no que además tienen en cuenta otros factores a la hora de valorar su vida laboral, y decidir si permanecer o no en una empresa. Dichos factores, según Forbes y por resumir, son:
El reconocimiento
La conciliación
El trabajo en equipo
El respeto por los horarios laborales
La existencia de un plan de carrera
Los retos
Un equipo directivo referente
De todos ellos, el trabajo en equipo es quizá uno de los principales ingredientes de un clima laboral sano, y un clima laboral sano repercute en la productividad de forma positiva. En Datarmony usamos los datos para optimizar las relaciones y asegurar un entorno de trabajo en el que la gente esté a gusto.
Grupos, grupos y más grupos
Toda actividad humana genera grupos que comparten ciertas características. Entender lo que define a estos grupos permite tomar decisiones más adecuadas con respecto a ellos. El tipo de decisiones que pueden adoptarse depende de la naturaleza de los grupos y ésta, a su vez, depende de los datos que se han utilizado para detectarlos.
Por ejemplo, si los datos que tenemos están relacionados con los patrones de compra, los grupos que encontraremos estarán relacionados con distintos tipos de clientes o potenciales clientes según sus hábitos de consumo, a los que podremos lanzar acciones de comunicación diferenciadas. Este sería un claro ejemplo de aplicación de clusters en terreno del marketing.
Clusters según patrones de comunicación
Si, en cambio, analizamos los patrones de comunicación de las personas que conforman una empresa, encontraremos grupos de empleados que se comportan de forma similar a la hora de comunicarse con los demás.
En Datarmony, y como complemento al análisis de redes que realizamos de forma periódica, generamos clusters con los datos de interacción disponibles en los registros de uso de las cuentas corporativas de correo, Meet y Calendar, y en el programa de gestión de proyectos.
Si el análisis de redes nos permite ver si las empresa tiene una comunicación fluida y compacta, y detectar aquellos casos en los que la situación de una persona dentro de la red necesita atención, el análisis de clusters nos permite ver aquellos grupos de personas que comparten patrones similares de comunicación dentro de la organización.
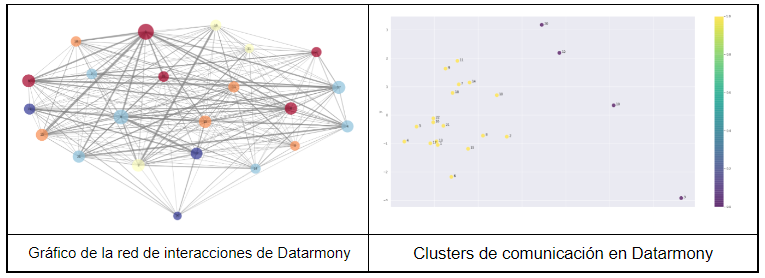
Adicionalmente, y no menos importante, también nos ayuda a detectar aquellos casos que no pertenecen a ningún cluster, puesto que sus hábitos de comportamiento en el aspecto analizado no son similares a ningún grupo.Clusters de comunicación en Datarmony. K-Means, k = 2.
Ambos análisis (el de redes y el de clusters) son complementarios, porque muestran la misma realidad desde diferentes puntos de vista. No olvidemos que en ambos hemos utilizado los mismos datos.
Dos caras de una misma moneda
El primero nos da una idea de la fluidez de la comunicación y de la posición de las personas en la red. El segundo nos indica quiénes conforman los grupos, y quiénes se quedan fuera. Las dos caras de una misma moneda que permite saber, por un lado, quién está aislado y necesita ayuda, y por otro en qué grupo deberían estar las personas según su perfil.
Es importante destacar que una situación concreta no es ni buena ni mala a priori, y depende de los perfiles incluidos en el análisis. Hay gente que por su trabajo es normal hallarlos en el centro de la red, y formando parte de un cluster determinado. Otras personas, en cambio, encuentran su posición normal en la periferia, y quizá en un cluster menos compacto o directamente en ninguno.
Los que hay que mirar con lupa son aquellos casos cuya posición en la red o su clasificación dentro de los clusters no se corresponde con lo que cabría esperar según la naturaleza de su trabajo.
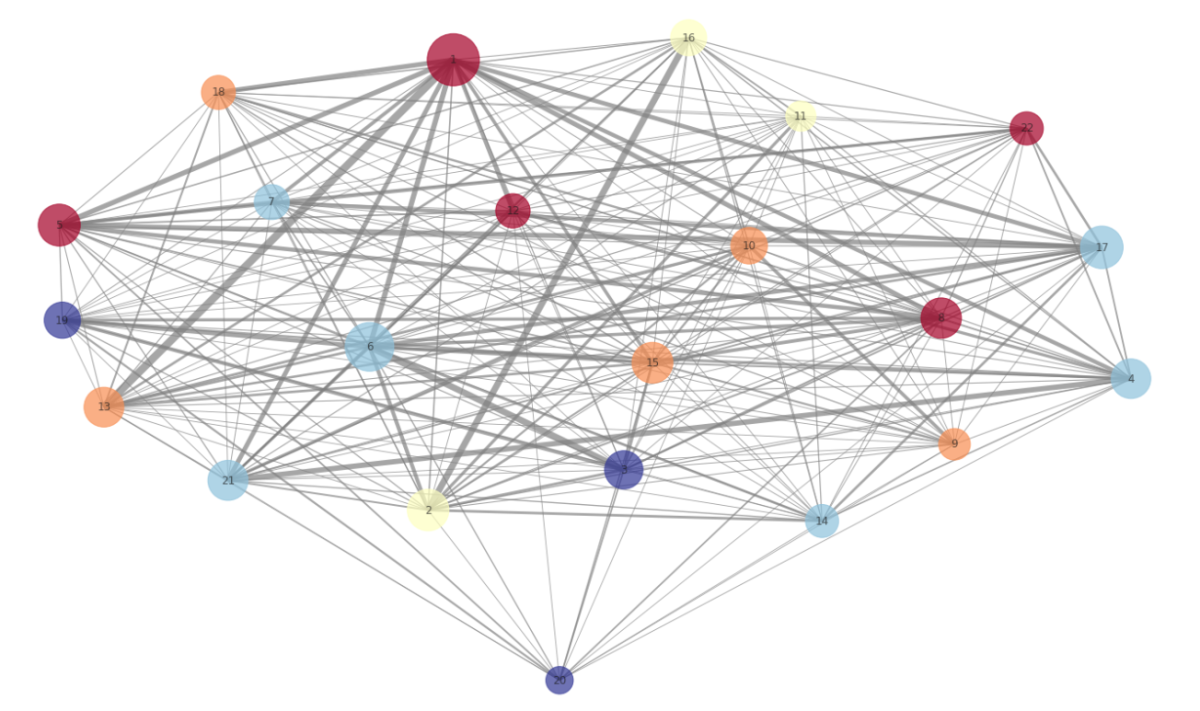
Los grupos no sólo dependen del tipo de datos incluidos en el modelo, también del algoritmo que se use para detectarlos, y de cómo se ajusta dicho algoritmo. El gráfico de clusters incluido anteriormente se ha hecho tras desarrollar un análisis de componentes principales (PCA), y aplicar el modelo de clusterización conocido como K-Means. En este caso concreto, el número de clusters predefinido ha sido establecido en 2 (seleccionado tras realizar un análisis de Silueta).
Inciso: ¿por qué PCA?
El análisis de componentes principales se usa a menudo para reducir el número de dimensiones con las que se trabaja para construir un modelo. Demasiadas dimensiones exigen muchos datos, y no garantizan buenos resultados. Por otra parte, la única manera de presentar un gráfico en dos dimensiones de los clusters es trabajar con las dos componentes principales (PCA-1 y PCA-2). Esto es lo que nos permite visualizar de forma sencilla los grupos encontrados. Recordemos que los seres humanos no podemos visualizar nada por encima de tres dimensiones. Y tres dimensiones en una pantalla de dos ya es complicado.
Volviendo al tema principal
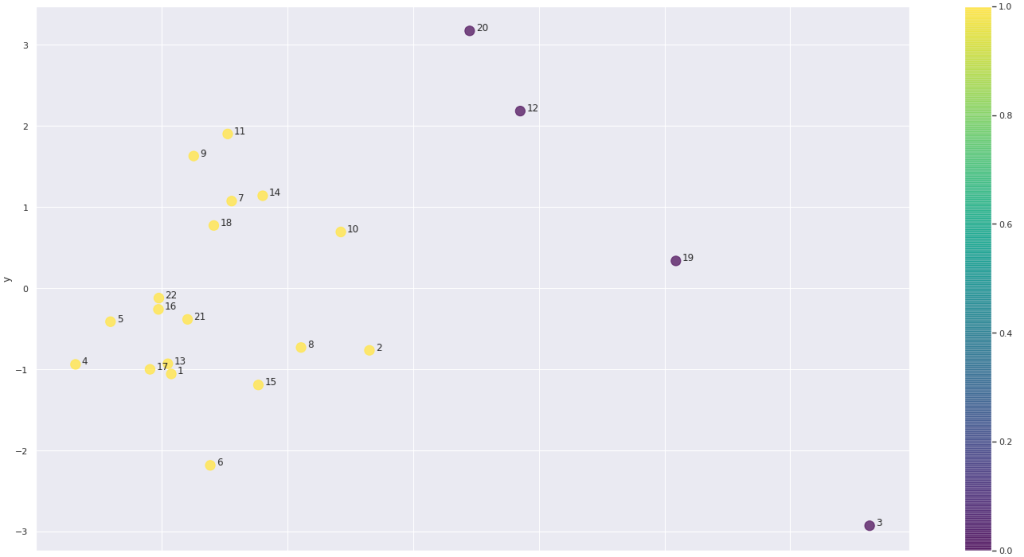
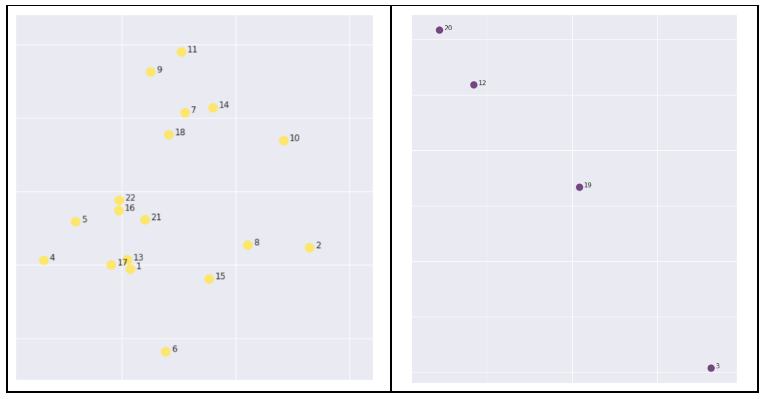
El resultado nos ha permitido detectar dos grupos. Los datos están anonimizados por razones de privacidad, pero quienes trabajamos en Datarmony podemos determinar a quién representa cada punto.
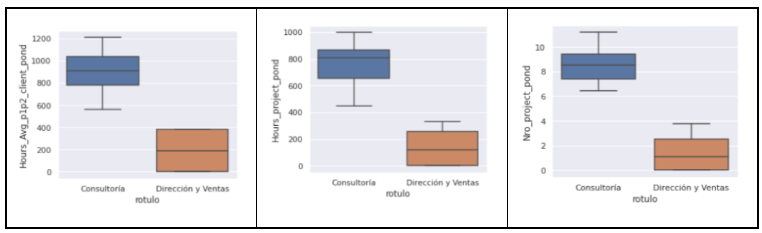
K-Means (con k = 2) genera dos clusters, amarillos y morados. Los amarillos son gente que está más en contacto entre sí y que trabaja en projectos (más de consultoría/producción). Los morados son en su mayoría gente de estructura (dirección, ventas, marketing y estrategia).
Los grupos están lejos de ser óptimos, aunque tienen cierta lógica (no olvidemos que estamos representando una realidad multidimensional en solo dos dimensiones). DBSCAN clustering (otro algoritmo de clusterización), por ejemplo, podría poner a los puntos morados y algún amarillo fuera de cualquier grupo.
Estas diferencias provienen de cómo funcionan los algoritmos. En K-Means todo punto debe pertenecer a un cluster (es un representante de lo que se conoce como Hard Clustering). En DBSCAN, en cambio, puede haber puntos que no pertenezcan a ningún cluster.
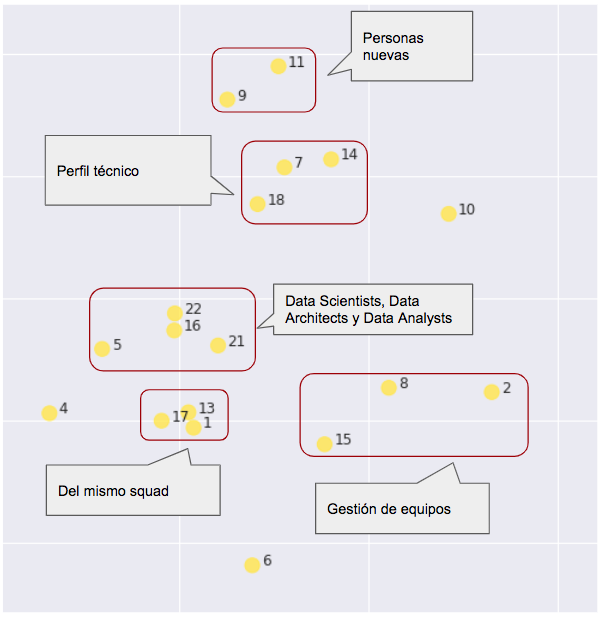
Siguiendo con K-Means, que en este caso concreto arroja los resultados más interpretables, y más acordes con la situación real (no olvidemos que el conocimiento de campo es esencial para interpretar correctamente los resultados), incluso dentro de los amarillos hay subgrupos definidos. Aunque la característica común es que se trata de comportamientos más relacionados con consultoría, producción y desarrollo de proyectos, también se ven otras cosas:
En cuanto a los morados:
Los morados en realidad no son un grupo compacto. Su forma de operar es muy diversa, pero comparten una realidad incuestionable: la mayoría no es gente de producción. No son personas involucradas en el desarrollo de proyectos. K-Means, con todos sus defectos, e incluso con la pérdida de información asociada a una reducción dimensional, ha sido capaz de ver esto.
La justificación de todo el análisis
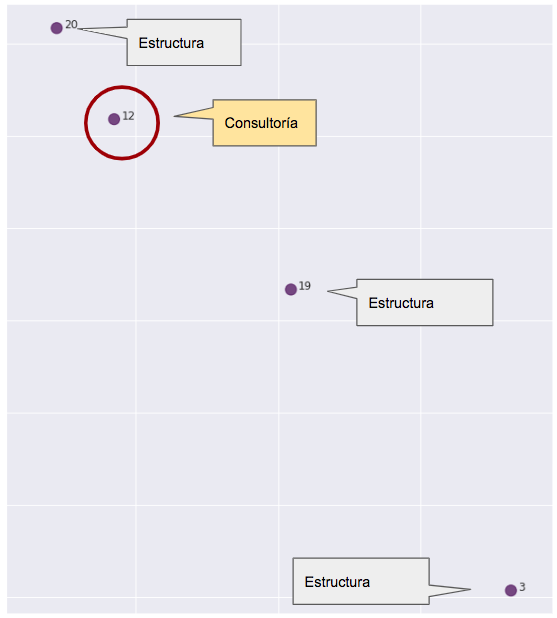
Pero aquí encontramos aquello que hace que todo este análisis valga la pena: el punto 12.
El punto 12 es un perfil de consultoría. La pregunta no es tanto ¿por qué está entre los morados?, sino más bien ¿por qué no está con los amarillos?
El análisis de redes no muestra esto, y el de clusters no dice nada sobre la calidad de la comunicaciones. De hecho, los puntos destacados en ambos gráficos ni siquiera representan a la misma persona, porque cuentan cosas distintas. Pero ambos juntos nos cuentan una historia completa, y nos enseñan facetas que por sí solos no pueden mostrar.
Con esta información, tanto managers como RRHH pueden investigar por qué los patrones de comunicación del punto 12 (no lo olvidemos, es una persona concreta) son tan distintos a los que se supone que debería tener según su puesto de trabajo. Puede que no haya ningún problema, puede que todo sea normal y que la persona esté operando de enlace entre ambos mundos. Pero también puede pasar que ese comportamiento se deba a problemas de comunicación que deban ser resueltos para el bien de todos.
Las diferencias
Durante todo el post hemos mencionado que los grupos de un mismo cluster comparten características similares pero, ¿qué hace que los amarillos y los morados sean diferentes?
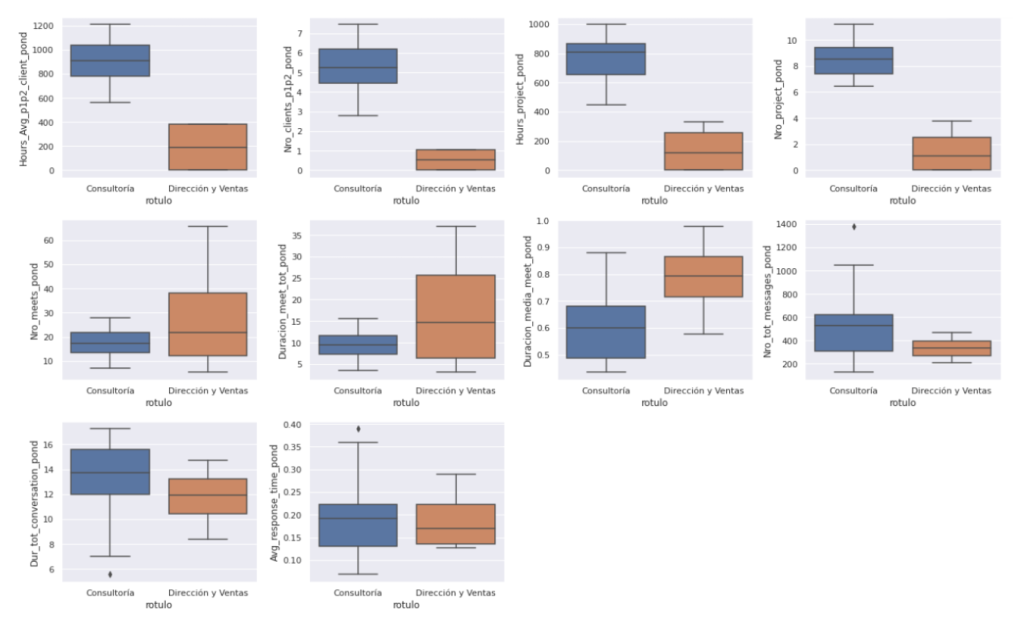
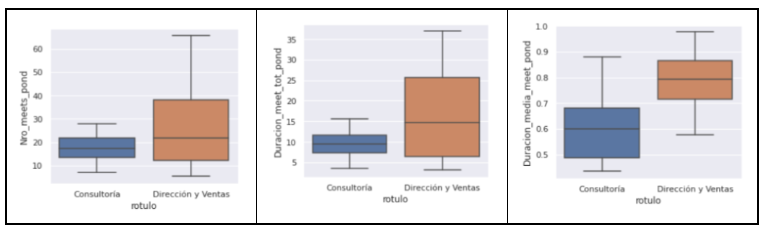
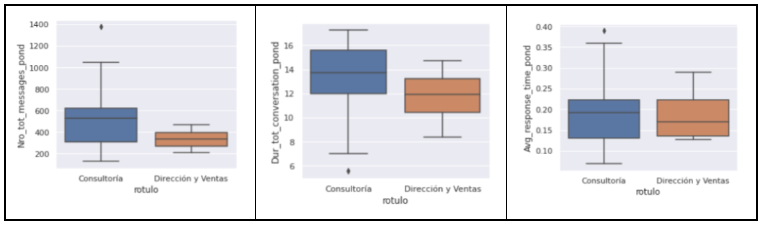
Si comparamos la distribución de las variables con las que se ha construido el modelo, vemos que algunas separan a los grupos de forma muy clara. Aquí, por sencillez, hemos llamado a los amarillos como “Consultoría” y a los morados como “Dirección y Ventas”, aunque en la práctica esto sea una simplificación:
Por ejemplo, Consultoría dedica mucho más tiempo a tratar con los clientes que Dirección y Ventas, y ocupa mucho más tiempo en proyectos, como es lógico:
Dirección, por su parte tiende a reunirse más veces, durante más tiempo:
En otros aspectos como el número de mensajes, la duración total de las conversaciones entre personas, y el tiempo medio de respuesta, los datos no diferencian claramente a los grupos. En otras palabras, en estos aspectos ambos clusters son similares:
Con esta información podemos acercarnos al punto 12 y ver si necesita apoyo. A lo mejor está participando en reuniones muy largas, lo que podría afectar a su productividad. Quizá no está integrado de forma clara en producción, y está asumiendo tareas más de estructura. En el peor de los casos está aislado y no se le están dando tareas de producción, (entonces se vería en el diagrama de red ocupando una posición periférica).
De nuevo, es necesario decir que a priori la situación no tiene porqué ser negativa. La realidad se debe establecer con un análisis cualitativo. Lo importante es que gracias a los datos sabemos donde debemos poner el foco para optimizar la comunicación en la empresa.
Cloud Computing: las 10 predicciones de Google para 2025
Daniel González & Felipe Maggi
07/12/2022
La Red está llena de predicciones. Algunas se basan en datos y son más o menos lógicas, otras, en cambio, son de dudosa fiabilidad. Algunas parecen tener todos los puntos para hacerse realidad, y no lo hacen, y otras, por las que nadie apostaría, acaban siendo parte de nuestro día a día.
Hablar sobre el futuro siempre tiene un riesgo, porque el futuro tarde o temprano acaba siendo el presente, y es muy fácil comparar lo que se pensaba que iba a suceder, con lo que realmente acaba sucediendo.
MsSaraKelly, CC BY 2.0, via Wikimedia Commons. Graffiti in Shoreditch, London
A Peter Drucker (1909-2005), reconocido consultor y profesor de negocios, se le atribuye la famosa frase “la mejor forma de predecir el futuro es crearlo”. Google lleva años creando parte de nuestro futuro, y convirtiéndolo en presente. Eso no significa que siempre acierte (¿alguien se acuerda de Google Plus?), pero al menos hace que prestemos atención cuando sacan la bola de cristal, y empiezan a decir eso de veo veo…
Otra de las cosas de las que Internet está lleno es de contenidos (algo que incluye a las predicciones). La cantidad de información es mucho mayor de lo que podemos abarcar, aun cuando nos focalizamos en un tema concreto.
En Datarmony estamos constantemente buscando temas en los que realmente valga la pena profundizar. En algunos casos vamos a tiro hecho, en otros nos ayuda la suerte (la serendipia, si nos ponemos cultos). Independientemente de cómo los encontramos, si vemos algo interesante nos gusta compartirlo, destacando lo más importante.
Hace unos días revisando los videos disponibles de Google Cloud Next, encontramos uno titulado “Top Ten Cloud Technology Predictions” para antes de 2025, que nos ha llamado la atención. No creemos que todas estas predicciones se hagan realidad al pie de la letra, pero algunas tienen muchas papeletas. Vamos a comentarlas una por una.
1. Durante los próximos dos años seremos testigos de un gran crecimiento en la adopción de los principios del diseño neuro inclusivo entre los desarrolladores.
Según Jim Hogan, líder en Google Cloud de Innovación y Accesibilidad, el 20% de las personas experimentan, interpretan y procesan la información de forma diferente al 80% restante, conformando una neurodiversidad que debe tenerse en cuenta. Hogan aconseja a los desarrolladores de software respetar los siguientes principios:
Diseñar de forma simple y clara.
Evitar elementos que generen distracción como las ventanas emergentes.
No utilizar colores demasiado brillantes ya que destacarían demasiado.
Aplicar patrones de diseño predecibles e intuitivos para no confundir al usuario.
Establecer un ambiente adecuado pensando en si ese elemento ayuda a establecerlo o solo es un extra que causa distracción.
Evitar puntos de presión que requieren una reacción rápida por parte de los usuarios.
Lo que pensamos en Datarmony
No dejan de ser interesantes pero, y que quede entre nosotros, son a grandes rasgos los mismos principios de diseño que venimos escuchando desde hace años, con un poco más de neuro y de ciencia en el encabezado.
2. Cuatro de cada cinco desarrolladores utilizarán código abierto cuidadosamente seleccionado.
En el video, se usa la expresión “curated open source”, que tiene una traducción no demasiado directa al idioma de Cervantes, pero que puede entenderse como lenguajes seleccionados, organizados y presentados adecuadamente. Lo importante de esta predicción es que pone el foco en el código abierto (todos sabemos que se trata, mayormente, de Python).
Eric Brewer, vicepresidente de Infraestructura de Google Cloud comenta que el código abierto se ha extendido enormemente, pero que tiene vulnerabilidades importantes. El código abierto seleccionado disminuiría el riesgo asociado, puesto que opera con paquetes seguros que pueden actualizarse en caso de ser necesario.
Lo que pensamos en Datarmony
Lo interesante aquí es que grandes empresas como Google se hayan rendido al código abierto, y que eso suponga una preocupación seria a la hora afrontar sus posibles desventajas, como el tema de la seguridad. Es una forma inteligente de adelantarse a los argumentos de posibles detractores.
3. El 90% de los flujos de operaciones de seguridad serán automatizados y gestionados como código.
Imán Ghanizada, jefe global de Operaciones de Seguridad de Google Cloud, asegura que la mayoría de las operaciones de seguridad serán automáticas. Actualmente hay demasiados entornos complejos de datos y muchos posibles atacantes, en comparación al número de personas con conocimientos sobre ciberseguridad. Según él, la solución pasa por apoyarnos en las nuevas tecnologías con el fin de detectar las amenazas, reduciendo el problema a desarrollar pautas de detección.
Lo que pensamos en Datarmony
Ponerlo sobre el papel de forma tan clara le confiere cierta relevancia, pero como predicción viene a ser similar al huevo de Colón. Ahora mismo la base de la lucha contra amenazas es la detección de patrones.
4. La Inteligencia Artificial será el principal factor impulsor de la semana laboral de 4 días.
Según Kamelia Aryafar, directora de Ingeniería de Google Cloud, es probable que la Inteligencia Artificial reduzca la carga laboral en un 20%, y que aumente la productividad al mismo tiempo, gracias a que hará más felices a los empleados.
En cuanto a las ventas, y debido a que la Inteligencia Artificial puede hacer cierto tipo de tareas de forma más eficiente, se prevé que los equipos comerciales generarán un 40% más de conversiones.
Lo que pensamos en Datarmony
Creemos que este tipo de afirmaciones merecen cierta reflexión. Cuando los ordenadores se generalizaron a nivel profesional, lo que antes se hacía en 20 horas pasó a hacerse en minutos, pero la jornada laboral de los que trabajamos con ordenadores no ha disminuido en la misma medida, porque se asignan (o asumimos) más tareas que deben ser resueltas en el mismo periodo de tiempo. En general no hemos acortado la jornada, hemos aumentado el número de cosas a hacer.
La semana laboral de cuatro horas es un asunto que no solo depende de cómo evolucione la Inteligencia Artificial y su adopción a nivel empresarial. Es necesario también un consenso social al respecto.
Sobre el tema de la felicidad, bueno, nos limitaremos a decir que la IA, como toda herramienta en manos de los seres humanos, puede ser usada de forma positiva o negativa. De nosotros depende.
Con respecto a las conversiones, es raro que a la hora de hablar de una nueva tecnología no se le atribuyan propiedades milagrosas en el terreno comercial. Puede que, efectivamente, dicha tecnología sea realmente disruptiva. Sin embargo, nadie comenta que si todos los actores la adoptan al mismo tiempo el efecto milagroso se diluye, puesto que la competencia estará haciendo lo mismo que nosotros. La clave aquí es que, si apostamos por algo, es mejor ser de los primeros (y esta es también una afirmación de perogrullo).
5. El 90% de los datos serán accionables a tiempo real gracias al Machine Learning.
Irina Farooq, directora de Gestión de Productos de Análisis Inteligente de Google Cloud, asegura que no queda mucho para que podamos operar con los datos a tiempo real de manera segura, sin esperar a validarlos.
Lo que pensamos en Datarmony
Esto lo vemos posible siempre que se trate de datos que por su naturaleza no requieran de validación previa, es decir, que no sean datos sesgados de ninguna manera, y que se recojan de forma que no puedan alterarse antes de ser procesados. ¿Alguien nos puede dar algún ejemplo?
En teoría, el Blockchain puede hacer eso, pero nos gustaría ver aplicaciones de esta tecnología más allá de las criptomonedas, las transacciones bancarias y el seguimiento de procesos logísticos, antes de lanzar las campanas al vuelo. Todavía estamos peleando para asegurarnos de que los datos recogidos por herramientas de medición web sean fiables, y aún estamos a lejos de poder confiar a ciegas en ese tipo de información.
6. Desaparecerán las barreras entre las bases de datos transaccionales y analíticas.
Andi Gutmans, vicepresidente y gerente general de Bases de Datos de Google Cloud, comenta que, tradicionalmente, las arquitecturas han separado las cargas de trabajo transaccionales y analíticas porque las bases de datos subyacentes se construyen de manera diferente.
Las bases de datos transaccionales están optimizadas para acelerar la escritura y la lectura, mientras que las bases de datos analíticas están optimizadas para agregar grandes conjuntos de datos.
Esto, a primera vista, parece lógico, hasta que caes en la cuenta de que muchos procesos necesitan información de ambas tablas, lo que repercute en una disminución del rendimiento.
Lo que pensamos en Datarmony
Aquí vemos algo interesante. Esta predicción la queremos seguir de cerca. Vamos a investigar más al respecto y seguramente publicaremos un post relacionado.
7. Más de la mitad de las decisiones de infraestructura en la nube se automatizará en función de los patrones de uso.
Amin Vahdat, vicepresidente y gerente general de Servicios de Infraestructura de Google Cloud, asegura que, gracias al nuevo hardware que tendrá la nube, las decisiones de infraestructura se adoptarán de forma automática en función de los patrones de uso de las organizaciones, haciéndolas más y eficientes y menos complejas de cara a las empresas.
Lo que pensamos en Datarmony
Entendemos esto como una evolución del concepto de autoescalado que ya tienen los entornos en la nube.
8. Tres de cada cuatro desarrolladores adoptarán la sostenibilidad como principio.
Según Steren Giannini, gerente del Equipo de Producto de Google Cloud, las empresas deben tomar consciencia de los problemas de sostenibilidad. Google colabora con ellas poniendo a su disposición regiones de procesado de datos con bajas emisiones de CO2.
Lo que pensamos en Datarmony
Aquí hay mucho que hablar. Google haría mucho a favor de la disminución de la huella de carbono ayudando a detectar el código basura instalado en millones de webs activas (ese que dejamos puesto después de testear herramientas, o de dejar de usarlas), y que generan llamadas inútiles a los servidores.
9. Más de la mitad de las organizaciones cambiarán de proveedor principal de servicios en la nube.
Richard Seroter, director de Relaciones con Desarrolladores y Gestión de Productos comenta que, actualmente, muchas empresas trabajan con diferentes proveedores de servicios en la nube, dividiendo datos y procesos y dificultando la operativa de datos entre entornos.
Según él, es muy probable que las empresas cambien su proveedor de nube principal en cuanto se sincronicen los entornos. Esto permitirá, por ejemplo, trabajar con BigQuery datos almacenados en una nube distinta a Google Cloud o, incluso, realizar cambios en un entorno trabajando desde otro.
Lo que pensamos en Datarmony
En general, y tras una época en la que están activas diversas opciones para cierto tipo de servicios, la economía de mercado acaba por hacer limpieza, dejando a unos cuantos actores principales. Por un lado, eso facilita la elección por parte de las empresas, y asegura estabilidad. Por otro, y en según qué entornos, acabamos en manos de unos cuantos que monopolizan el mercado. La predicción, en este caso, es casi una profecía autocumplida.
10. Más de la mitad de las aplicaciones comerciales serán creadas por usuarios que no se identifican como desarrolladores profesionales.
Jana Mandic, directora de Ingeniería de Google Cloud, concluye afirmando que usuarios sin conocimientos técnicos avanzados serán capaces de desarrollar aplicaciones, gracias a herramientas como AppSheet.
Lo que pensamos en Datarmony
Prometedor, para los que no son desarrolladores profesionales, claro. De todas formas, tendremos que ver el nivel de estas aplicaciones comerciales desarrolladas por usuarios “no profesionales”.
Conclusión sobre Cloud Computing y las 10 predicciones de Google para 2025
Muchas de estas predicciones son cosas que ya están pasando, y alguna que otra es una reinterpretación de algo ya conocido. Sin embargo, como indicadores de posibles tendencias, son dignas de atención.
En Datarmony estamos atentos a ellas, sobre todo en lo relacionado con ciberseguridad, arquitectura de Bases de Datos e Inteligencia Artificial, puesto que es posible que, si no todas, algunas marquen el paso de los servicios en la nube. Cuando eso suceda, podremos dar el soporte adecuado a nuestros clientes en materia de aprovechamiento de los datos.
El análisis de redes y la optimización del clima laboral
Felipe Maggi
07/12/2022
Es un hecho contrastado que el paradigma de gestión de recursos humanos ha evolucionado enormemente desde los albores de la revolución industrial. No todas las empresas, o empresarios (léase Twitter, de Elon Musk), lo tienen tan claro, pero la realidad ya se encargará de poner las cosas en su sitio.
Hace tiempo que la productividad dejó de ser el único indicador relacionado con la fuerza laboral. Hoy en día tienen mucho peso conceptos como el índice de rotación (la relación entre las personas que se incorporan y las que se marchan en un periodo de tiempo determinado).
En otras palabras, además del número de tornillos que se aprietan, ahora también nos preocupa que quede alguien en la cadena de montaje apretando tornillos.
Workers on the first moving assembly line put together magnetos and flywheels for 1913 Ford autos Highland Park, Michigan. Unknown author. Public domain, via Wikimedia Commons
Reforzar la retención de talento es, actualmente, uno de los principales dolores de cabeza de empresas modernas. El ultimatum de Musk a los empleados de Twitter, por ejemplo, quizá habría funcionado hace 50 años, pero hoy, en países ricos, la gente responde ante esas cosas con un “ahí te quedas”
Pero no hace falta llegar a esos extremos para que la gente decida probar suerte en otros sitios. En los países ricos, insisto, con democracias relativamente bien establecidas, no solo las empresas valoran a sus empleados; los empleados también valoran a sus empresas.
Si desde la perspectiva empleado-empresa el principal indicador era tradicionalmente el salario, ahora, y según Forbes, los puntos más valorados por las personas con respecto a su vida laboral son:
El reconocimiento.
La conciliación.
El trabajo en equipo.
El respeto por los horarios laborales.
La existencia de un plan de carrera.
Los retos.
Un equipo directivo referente.
Según donde se mire el salario aparece o no, y el orden cambia (asumiendo que el orden tenga algo que ver con la importancia que se otorga a cada punto) pero, en definitiva, está claro que para retener talento las empresas tienen mucho más trabajo que limitarse a subir sueldos.
Trabajo en equipo y análisis de interacciones
De los puntos mencionados anteriormente, en este post nos centraremos en el análisis de redes y el trabajo en equipo, un elemento directamente relacionado con el clima laboral, y la felicidad de los empleados.
La felicidad laboral es un elemento
esencial de la productividad
Parece existir cierto consenso en afirmar que la felicidad laboral es un elemento esencial de la productividad (mira por donde, hemos vuelto al principio). Por lo tanto, analizar las relaciones entre los empleados, buscando la manera de mejorar la calidad de dichas relaciones y de potenciar el trabajo en equipo debería tener consecuencias directas, y positivas, en la retención de talento y los resultados económicos de la compañía.
Es importante destacar, para dar contexto a lo que viene a continuación, que el análisis de las relaciones entre las personas busca entender la naturaleza de la red organizacional, y detectar aquellos puntos en los que es necesario intervenir para mejorar las cosas. En ningún caso se pretende fiscalizar esas relaciones.
Explorando la situación
En Datarmony no queremos que se nos aplique aquello de “en casa del herrero, cuchillo de palo”. Por eso, testeamos sobre nosotros mismos lo que predicamos para los demás. Con ese principio en mente, analizamos de forma constante nuestra red organizacional, y tomamos decisiones para reforzar la calidad de la misma.
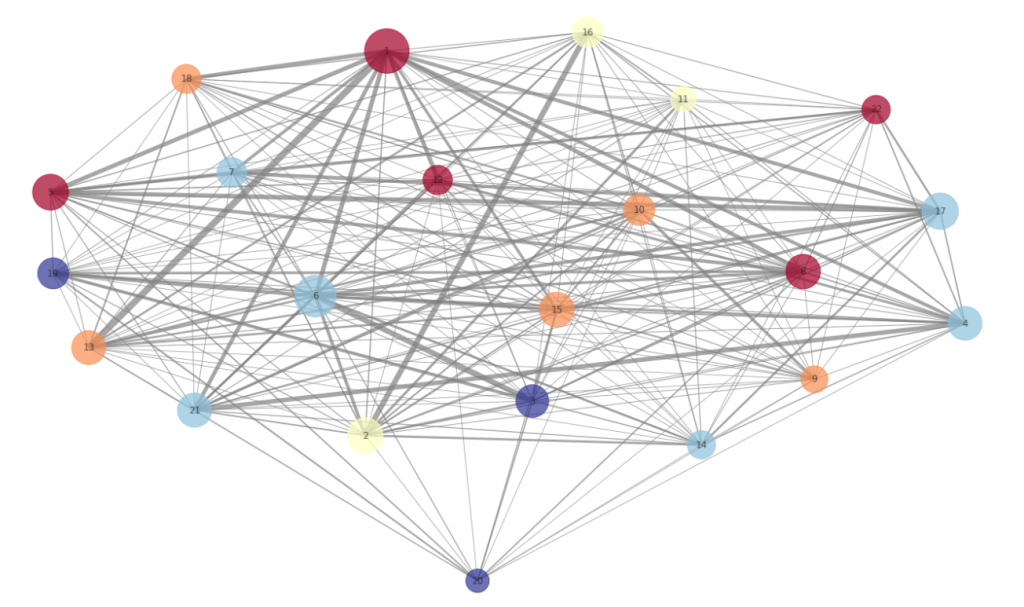
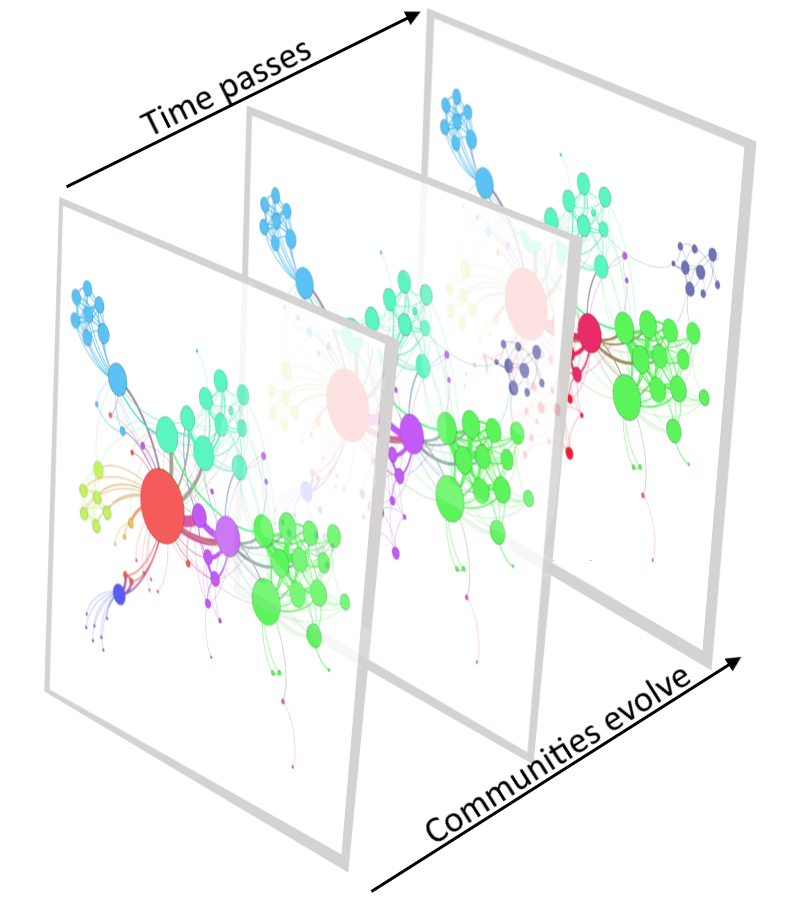
El análisis de redes mediante Machine Learning permite graficar las relaciones entre personas (se puede aplicar a otras cosas, pero vamos a dejarlo ahí para simplificar), y es un ejemplo de aprendizaje no supervisado.
La imagen que encabeza esta sección del post es el resultado final de un trabajo que incluye recopilación y tratamiento de datos, exploración y modelización, pasando por análisis de componentes principales (PCA) y clusterización.
Nuevos KPIs
El modelo no solo grafica el estado de cosas, si no que arroja indicadores de calidad de la red como:
La distancia media entre pares de nodos (los círculos del gráfico),
El diámetro de red
El radio de la red (o excentricidad)
El objetivo: contar con una red compacta
Sin entrar en detalles, podemos decir que mientras más compacta es una red, mejor. Una red compacta, en términos de la distancia media entre nodos, supone una situación en la que la comunicación entre los integrantes del equipo es fluida, y en la que, en general todos interactúan entre sí.
Adicionalmente, el modelo detecta quienes están en la periferia de la red, y quienes están situados más al centro (grado de centralidad). Los actores con mayor número de vecinos y relaciones tienden a situarse en el centro.
Esto no es, a priori, ni bueno ni malo. Hay personas dentro de la organización que deben ocupar posiciones centrales, y otras que es normal que se encuentren más hacia la periferia. La clave es detectar situaciones anómalas (gente que por su perfil y responsabilidades no está situada donde se espera). En estos casos, se analiza la situación de forma cualitativa, y se busca la manera de resolver el problema.
Evolución y tendencias del trabajo en red
Este tipo análisis permite observar la evolución de la red, y ver cómo se comporta cuando se producen cambios organizacionales importantes. Por ejemplo, en julio de 2022 entraron en la empresa cuatro personas.
Los nuevos compañeros siempre pasan por un proceso de adaptación, que supone encontrar su sitio, conocer y ganarse la confianza de los demás, y hacerse con el espíritu de la organización. Durante ese proceso, toda la red lo nota, sobre todo si el número de personas nuevas es grande con respecto al número total de personas en la empresa. Tras las nuevas incorporaciones, la distancia promedio entre los nodos aumentó ligeramente, denotando así que la calidad de la red se había resentido un poco.
Esto nos hizo trabajar para disminuir ese tiempo de adaptación, y así recuperar rápidamente nuestro flujo normal de comunicación, acompañando adecuadamente a los compañeros recién llegados.
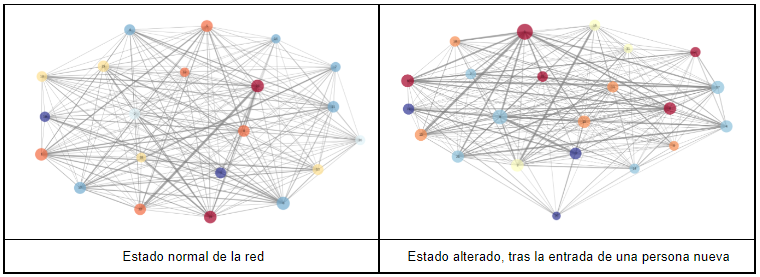
Otro ejemplo, más gráfico, es el siguiente:
La red de la izquierda muestra el estado “normal” del flujo de interacciones de Datarmony. A la derecha, se observa el efecto de la incorporación de una persona nueva (el punto inferior, separado del resto).
La red, a grandes rasgos, sigue siendo la misma, pero se ve claramente que la persona que acaba de entrar se halla separada del resto (situada anormalmente en la periferia). Ayudar a que esa persona se integre rápidamente es esencial para su bienestar laboral.
Imagine ahora que este mismo análisis se aplica en su empresa. Los ejemplos que hemos puesto con personas nuevas nos han permitido explicar y visualizar los efectos en la red, pero suponga que encuentra uno o varios casos como los de la red de la derecha, que afectan a gente que lleva tiempo trabajando.
Esas personas, con toda probabilidad, necesitan apoyo. Por alguna u otra razón están separadas del resto, aisladas. Quizá, para un caso concreto, es normal. Pero para aquellos que deberían interactuar con el resto por su tipo de trabajo, la situación es delicada.
Detectar estas situaciones nos permite emprender acciones para entender qué pasa, y cómo podemos ayudar a cohesionar al equipo. Es posible, por ejemplo, que esas personas deban ser presentadas a actores que ocupan posiciones centrales en la red, para aumentar sus opciones de interacción a través de ellos.
Con este tipo de información los responsables de Recursos Humanos pueden poner en marcha programas de integración de equipos, focalizándose en la gente que necesita más apoyo en ese sentido. Esto no sólo repercute en el bienestar de los afectados, sino también en todo el resto, puesto que la red se hace más compacta.
Esto no es ciencia ficción
Hasta aquí hemos ejemplificado un caso real de aplicación del análisis de redes. Sin embargo, aún puede sonar a ciencia ficción si no se dan detalles sobre cuestiones tan básicas como la procedencia de los datos.
En Datarmony trabajamos con la suite de Google, lo que nos da acceso a los eventos de registro de uso de las aplicaciones de comunicación corporativa. En concreto, para este análisis hemos utilizado los registros del correo electrónico, de Meet y Calendar. Adicionalmente, hemos incluido en el modelo la información proveniente de nuestro programa de gestión e imputaciones, que nos permite saber quiénes colaboran en los mismos proyectos.
Los registros no incluyen el contenido
de las comunicaciones
Antes de finalizar, de nuevo quiero recalcar que esto no se trata de Un Gran Hermano. Estos registros no contienen información sobre el contenido de las comunicaciones, simplemente ofrecen datos sobre los emisores y receptores de los mensajes, la fecha, el medio, etc… Otras suites de comunicaciones empresariales como la de Microsoft (Teams), ofrece registros similares. Todo administrador con privilegios suficientes puede descargar esa información.
Es importante que esto se entienda bien. Todo análisis, más ahora que las aplicaciones de Machine Learning e Inteligencia Artificial empiezan a asustar a la gente, puede generar reticencias si no se explica bien el objetivo del mismo.
Lo que hacemos en Datarmony lo hacemos para detectar posibles problemas de comunicación e integración, y para ayudar a los equipos a resolver esos problemas. Nuestros principios empresariales nos empujan a trabajar por el bien de todos nuestros compañeros, y eso siempre se tiene en cuenta cuando generamos y aplicamos nuestros modelos.
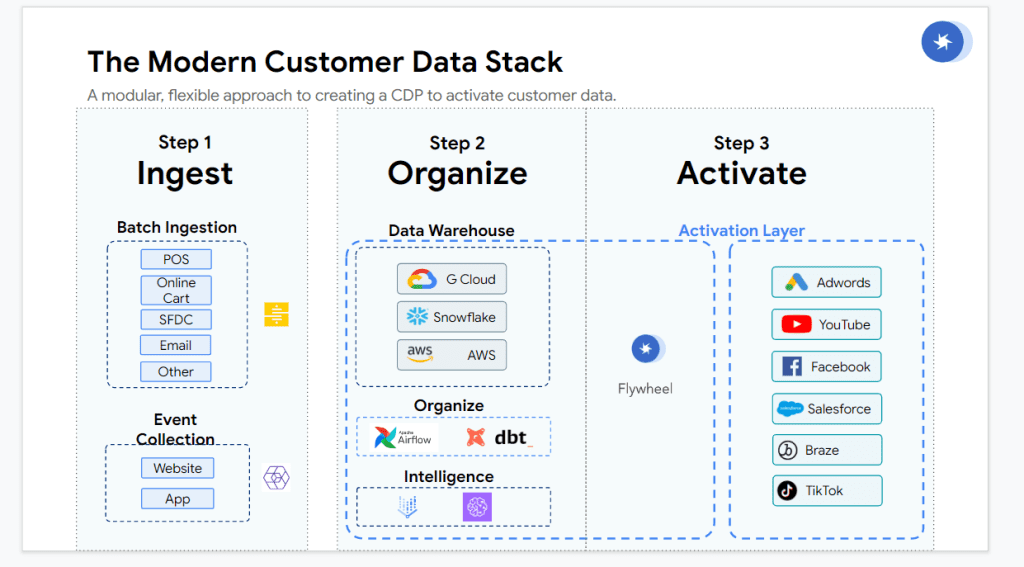
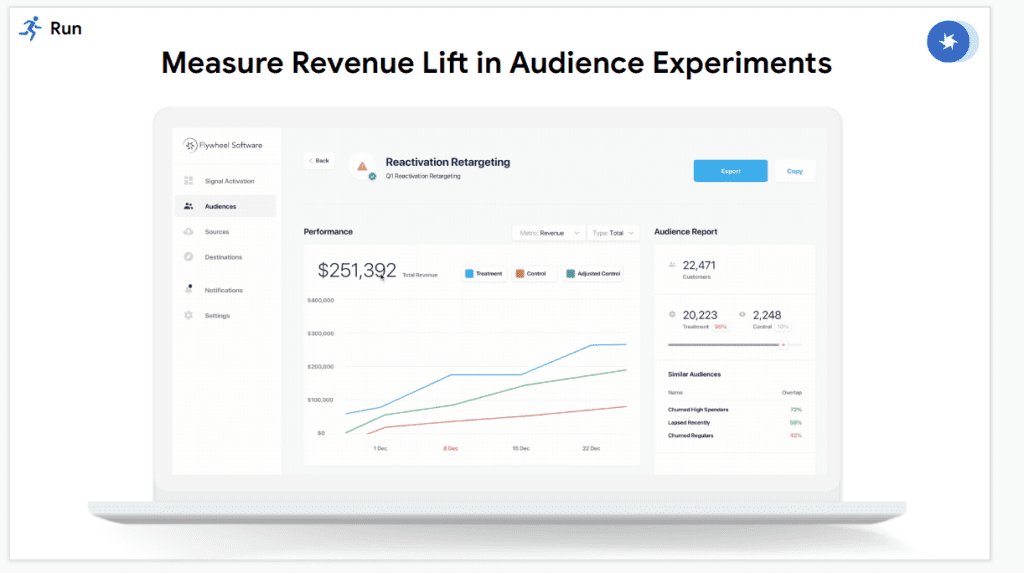
En este post presentamos un análisis de Flywheel para el enlace externo, una nueva herramienta que podemos introducir en nuestro data stack.
Flywheel es una plataforma de activación de datos que pretende simplificar la capa de activación del data stack actual.
Su intención es permitir a perfiles de marketing activar datos sin la necesidad del departamento de IT, ni conocimiento avanzado de SQL. Por lo tanto, flywheel es muy útil en ecommerce.
La idea es que el personal de marketing pueda generar audiencias desde una interfaz gráfica y exportar estos datos a otras plataformas.
Se introduciría en el flujo de activación de datos de esta forma:
No es ningún sustituto para Data Warehouses ni para plataformas de marketing como Facebook Ads o Adwords. Su objetivo es ser un puente entre los datos y sus plataformas de activación y acelerar el uso de los datos para mejorar las conversiones. En este sentido, es una herramienta especializada en cumplir una de las funcionalidades de un Customer Data Platform, por una fracción del coste.
¿Cuál es la función principal de Flywheel?
La función principal de Flywheel es generar audiencias utilizando datos 1st party que se alojan en un data warehouse como BigQuery o Snowflake. Es una herramienta muy accesible para usuarios que no tienen conocimientos de Data Science pero quieren crear campañas lo antes posible.
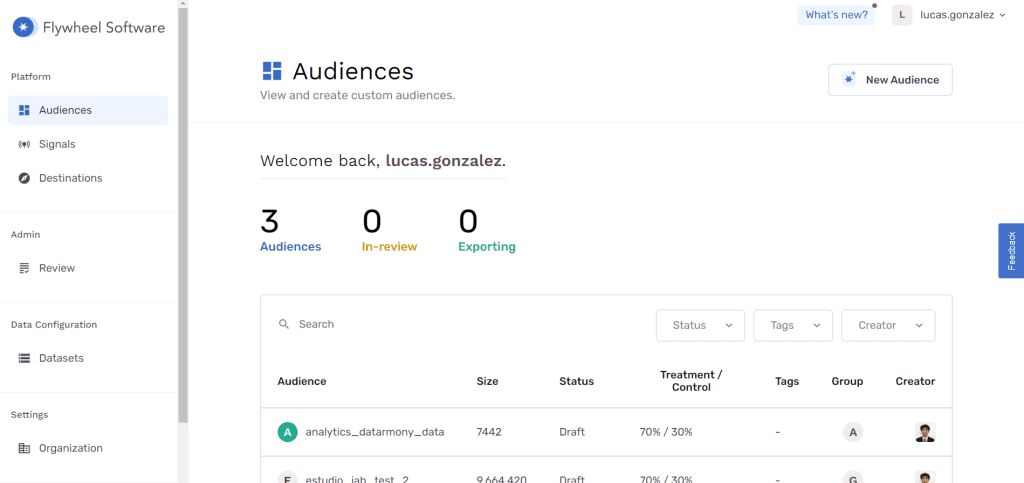
Su interfaz es la siguiente:
Podemos acceder a la herramienta desde un navegador web, por lo tanto no requiere instalaciónde ningún tipo. Desde esta interfaz podemos ver todo lo que se puede hacer con la herramienta, que incluye:
Importación de datos 1st party, sin necesidad de sacar los datos del data warehouse en cuestión. Esto es de especial importancia teniendo en cuenta el nuevo acuerdo de protección de datos Privacy Shield 2.0.
Generación de audiencias utilizando una interfaz gráfica.
Exportación de audiencias a plataformas de marketing.
Generación de experimentos con los que verificar la efectividad de las audiencias.
¿Cómo ayuda Flywheel al marketing?
Busca simplificar el sistema actual de generación y exportación de audiencias.
Actualmente, la única forma de hacerlo es mediante algún lenguaje como SQL, Python o R. Esta barrera hace que el proceso de lanzar una campaña dirigida sea mucho más lenta de lo ideal.
Flywheel empodera al marketing, debido a que se elimina la dependencia actual en equipos de IT, y acerca al cliente a la activación de sus datos lo más pronto posible.
¿Cómo funciona Flywheel?
En caso de utilizar BigQuery, el primer paso para utilizarlo es conectar una cuenta de servicio para que pueda acceder a nuestros datos. Como hemos mencionado antes, estos datos siempre estarán alojados en BigQuery, y nunca serán enviados a otro data warehouse.
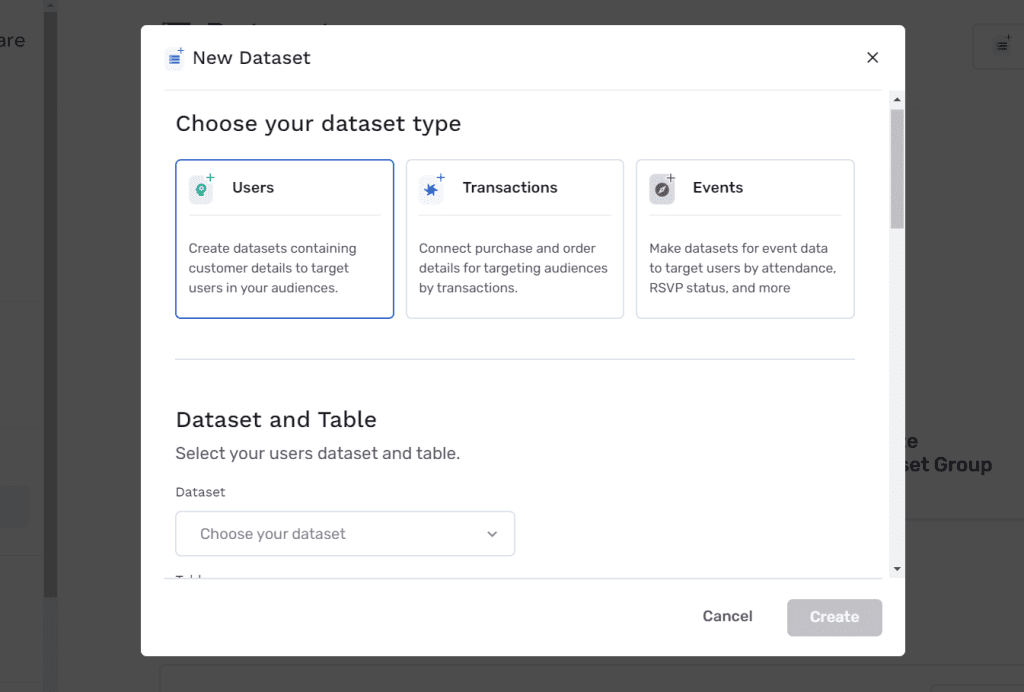
A partir de ahí, seleccionamos el dataset y la tabla que queremos usar:
En cuanto hemos creado el dataset, ya podemos ir a la sección de Audiencias para crear una. La generación de audiencias se hace desde una interfaz gráfica sencilla que intenta darnos toda la funcionalidad de SQL. Es intuitivo, responde rápidamente y da respuestas en tiempo real. Además, se está desarrollando una versión mejorada que ya tiene versión alpha.
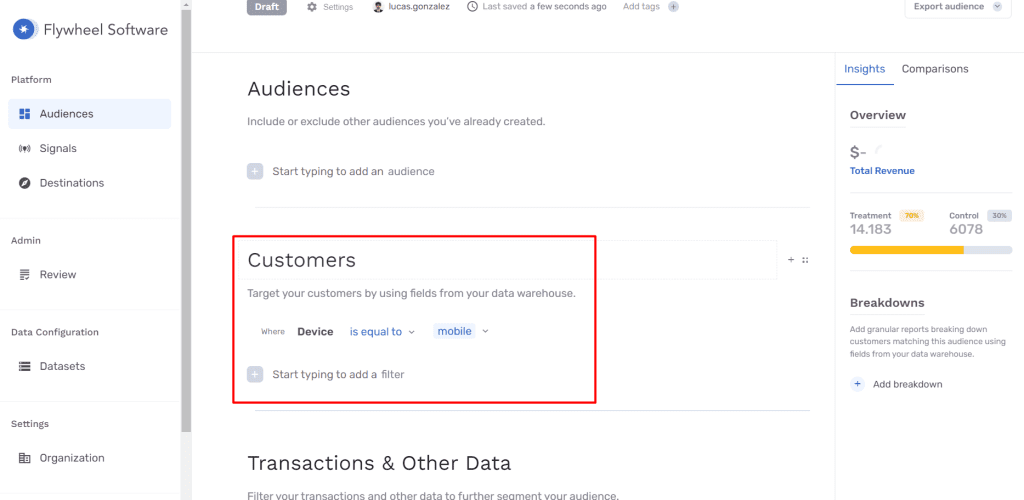
En la siguiente captura hemos creado una audiencia simple, en la que filtramos por usuarios mobile:
Ahora podemos exportar esta audiencia de forma directa a una plataforma de marketing como Facebook Ads, Google Ads o Snapchat. Esta audiencia se actualizará automáticamente con los datos que introducimos en BigQuery y podemos programar la exportación periódica de la audiencia.
En la sección de la derecha podemos crear una audiencia de control. Nos permite comparar las dos audiencias y comprobar la efectividad de nuestra audiencia personalizada:
Conclusiones sobre Flywheel y el inbound marketing
Tras haber experimentado con la herramienta, creemos que cumple su función y ocupa su rol en el flujo de activación de datos de forma satisfactoria.
Pensamos que puede ser especialmente útil para empresas sin un departamento de IT muy desarrollado, pero que tienen un gran deseo de utilizar sus datos 1st party, digitalizarse y mejorar su conversiones. Tras un poco de configuración, vemos perfectamente lo fácil que sería crear audiencias para alguien sin previa experiencia.
A pesar de todo esto, creemos que la herramienta aún requiere desarrollo de funcionalidades adicionales. Por ejemplo, utilizar machine learning para generar y recomendar audiencias utilizando un modelo sería una funcionalidad espectacular. Ahora mismo, cubre un nicho muy específico del flujo de activación, pero nada más.
En su estado actual, recomendamos al experto en marketing digital que busca sacar provecho de sus datos y activarlos ASAP, y no pretende utilizar todas las funcionalidades de un Customer Data Platform.
En el campo de los datos, y durante años, el principal escollo ha sido la activación. Ya desde los albores de la analítica digital, en los que los informes empezaban, o debían empezar, con un listado de hallazgos y recomendaciones, hasta hoy, en los que un modelo es capaz de predecir el comportamiento de nuestros clientes, el problema de la activación sigue en primera línea.
Para muchas empresas, pequeñas, medianas y grandes, hacer algo con los resultados que se obtienen a partir de los datos, ya sean resultados descriptivos, prescriptivos o predictivos, es un verdadero problema. Es la última milla que muy pocos recorren: la mayoría se ahoga después de haber nadado contra viento y marea, a pocos metros de la orilla.
Activar los datos de una empresa
Activar el dato es complejo, porque supone la coordinación de varios departamentos. Un simple análisis de campañas, que arroje unas cuantas recomendaciones de cambios y ajustes implica a Marketing, Diseño, Compras y probablemente a IT.
La activación de un modelo que clasifique a los clientes según su probabilidad de abandono, y cuyo output sea un listado de usuarios ordenados según esa probabilidad implica a Business Intelligence, IT, Marketing y seguramente al Centro de Atención de Clientes.
Esta coordinación no es sencilla, y a menudo salta las barreras del departamento que solicitó el análisis. La situación se reduce a lo siguiente: las iniciativas acaban juntando polvo en un cajón.
La solución adoptada por las grandes compañías tecnológicas ha sido la automatización de las acciones. Los modelos “analizan” la situación y el sistema reacciona de una manera que se supone beneficiosa para los objetivos de la empresa. En esta reacción, que a menudo es a tiempo real, o casi, no interviene el ser humano, y no implica, en el momento de adoptarse, a ningún departamento de forma directa.
Ejemplos de empresas que utilizan el big data
Amazon (perdón por el ejemplo, ya sé que es muy manido), hace esto cada vez que entramos en el sitio y vemos una selección de productos destacados basada en nuestras compras anteriores, y en lo que compran otros usuarios con gustos parecidos a los nuestros. Esto no significa que no haya habido coordinación interdepartamental. Marketing, Compras, Business Intelligence, Diseño, IT… Todos han trabajado para definir la estrategia de contenidos a mostrar, para desarrollar el modelo que decide a quién ofrecer qué, para preparar los textos y las imágenes, para contratar a los perfiles adecuados, etc… La clave, es que una vez definida la estrategia, en sentido amplio y en detalle, la activación corre sola.
Pero claro, Amazon es Amazon, y Google, Google… Y así podríamos seguir. La excusa para justificar que no hacemos lo que hacen Amazon y Google es que dichas empresas tienen mucho dinero, y muchos recursos tecnológicos. Pero la verdad es que si tienen dinero, es porque han sabido usar los recursos tecnológicos, y los datos. Este es el quid de la cuestión: lo que tienen estas empresas son datos. Pero el caso es que usted también los tiene. Vale, de acuerdo, quizá no el el mismo volumen y extensión, pero los tiene.
Cómo analizamos datos para tomar decisiones en Datarmony
Hoy en día cualquier empresa, de cualquier tamaño, genera datos suficientes como para poder trabajarlos. Nosotros mismos, sin ir más lejos, explotamos nuestros datos todo lo que la imaginación nos permite, y somos una consultora con veintiún empleados.
Por ejemplo, en Datarmony recogemos con una herramienta muy barata los tiempos dedicados a los proyectos, y contamos con Cuadros de Mando que nos muestran en todo el momento el estado de los mismos. Las tablas a partir de las que “pintamos” la información, nos permiten generar alertas automáticas cuando se cumplen ciertas condiciones en los parámetros de vida de los proyectos. Esto posibilita, entre otras cosas, controlar los costes de producción, y emitir facturas cuando llega el momento, con el objetivo de tener la caja lo más saneada posible.
Otro ejemplo: analizamos los flujos de comunicación dentro de la empresa, con los datos de correos, chats y reuniones, y usamos esa información para detectar problemas de funcionamiento de los equipos en materia de colaboración. Aplicamos para ello modelos de análisis de redes, y luego trabajamos los hallazgos con los encargados de RRHH y coaching interno. El objetivo es mejorar los resultados de la compañía, mejorando el entorno de trabajo. Si su empresa usa las herramientas de comunicación de servicios como Google Workspace o Microsoft, los datos para este tipo de análisis los tiene disponibles ¿Lo sabía?
En el terreno del Marketing Digital y la comunicación con los clientes, hay aspectos que se han automatizado mucho mejor que otros, es cierto. Aún no he visto funcionando en un cliente una solución que permita ajustar de forma automática la inversión en distintos canales según la contribución real de éstos a las conversiones. Importante: hablo a nivel de canales, no de campañas, donde las plataformas aplican sus algoritmos para maximizar el beneficio. La pregunta, capciosa, es ¿para maximizar el beneficio de quién?
En cambio, ejemplos de personalización de contenidos y ofertas hay muchos, y contrastados. ¿Por qué no aprovechar lo que ya existe? Es verdad que en este terreno hay todo un abanico de opciones que van desde lo más simple, herramientas de testing capaces de mostrar la versión que mejor convierte de una página o pantalla, hasta las complejas, que modelizan los datos para generar audiencias a las que presentan la experiencia que mejor se ajusta a sus características. Nos movemos de Google Optimize, a Dynamic Yield, por nombrar dos ejemplos en los extremos.
Big Data: Explosión de datos
Como ya hemos dicho, la activación de los datos siempre supone una fase previa en la que distintos departamentos se han puesto de acuerdo. La diferencia esencial entre las empresas que realmente activan sus datos, de forma continua, y las que no, radica que estas últimas se han puesto de acuerdo antes. La activación no exige que la gente esté encima, aunque solo sea para darle a un botón.
Pero seamos realistas. Adoptar procesos en los que la activación de los datos sea la norma no es algo que se pueda hacer de un día para otro. Paradójicamente, lo que a priori se ve como más complejo (la parte técnica), es lo más sencillo. Lo difícil es adoptar el esquema mental que hace posible este tipo de avances. Es a nivel estratégico y de madurez en la percepción de la importancia de los datos, en donde está el problema. La barrera no es técnica, es mental.
Por listar algunos escollos:
No somos conscientes de los datos que ya tenemos.
Pensamos que para sacarles provecho hay que hacer grandes inversiones en tecnología.
Vemos todo como demasiado complejo… “Esto es muy difícil”.
Damos por sentado que el equipo directivo no va entender las ventajas de un proyecto de activación de datos.
La lista podría ser mucho más larga, pero con estos cuatro puntos creo que resumo la esencia del problema.
Vamos a tratar de responder a cada uno de ellos:
Recursos de los que disponemos
¿Usa entornos de comunicación empresarial, registra transacciones, tiene algún sistema de gestión de clientes, debe gestionar stocks, ofrece servicios y cuenta con un departamento comercial, tiene web, cuenta con call center…? Con que haya respondido afirmativamente una vez, ya tiene datos que puede activar.
Inversión para activar el dato
La inversión necesaria, más que en tecnología, es en talento. Hay miles de herramientas gratuitas en el mercado que permiten recoger y almacenar datos y, si no son gratuitas, hay opciones muy baratas. Los mismo es aplicable en casos concretos, como la personalización de contenidos. En materia de almacenamiento y procesamiento, el advenimiento de los servicios de computación en la nube ha democratizado el entorno. Contar con un data warehouse hoy en día está al alcance de cualquier empresa, de cualquier tamaño. Lo mismo puede decirse a nivel técnico en lo referente al desarrollo de modelos y aplicación de Inteligencia Artificial. Los servicios en la nube que permiten almacenar los datos cuentan con la infraestructura necesaria para desarrollar dichos modelos, y subirlos a producción.
El talento necesario
Si cuenta con el talento adecuado, ya sea internamente, ya sea mediante una empresa colaboradora, se sorprendería de lo sencillo que resulta activar los datos, una vez que se tiene la estrategia adecuada, y las prioridades claras. El trabajo real es sentarse a pensar y decidir por dónde empezar. Desde Datarmony podemos proporcionar ese talento, y/o ayudar a formar un equipo interno necesario.
Colaboraciones
Busque la colaboración de una empresa especializada capaz de presentar un plan de activación de los datos a los directivos. Permita a dicha empresa estudiar su situación, a nivel de madurez en el terreno de los datos, y déjela desarrollar para usted una propuesta de activación que tenga en cuenta el punto de partida, y los objetivos finales. En Datarmony podemos hacerlo de forma que queden patentes las ventajas del proyecto.
Hace unos meses el administrador de etiquetas de google añadió la funcionalidad Cobertura de la etiqueta, en este enlace está disponible la documentación oficial:
Pero, en este breve post, damos algunas pinceladas de lo que nos encontramos al acceder a esta funcionalidad de Google Tag Manager.
Cómo validar las etiquetas de una página web
Este servicio nos permite validar si la etiqueta de Google está instalada correctamente en el sitio web. Es decir, lo que se va a revisar es si existe una llamada a gtag o que esté puesto el contenedor de GTM.
El Tag de Google se incluye cuando implementamos GA4 o Google Ads.
Para acceder a este servicio desde GTM, podemos hacerlo desde la pestaña “Administrador” de nuestro contenedor.
También desde la propiedad de GA4, accedemos al flujo de datos, en la parte de etiqueta de Google seleccionamos “Configurar ajustes de etiquetas” y dentro pulsamos en la pestaña “Administrador”
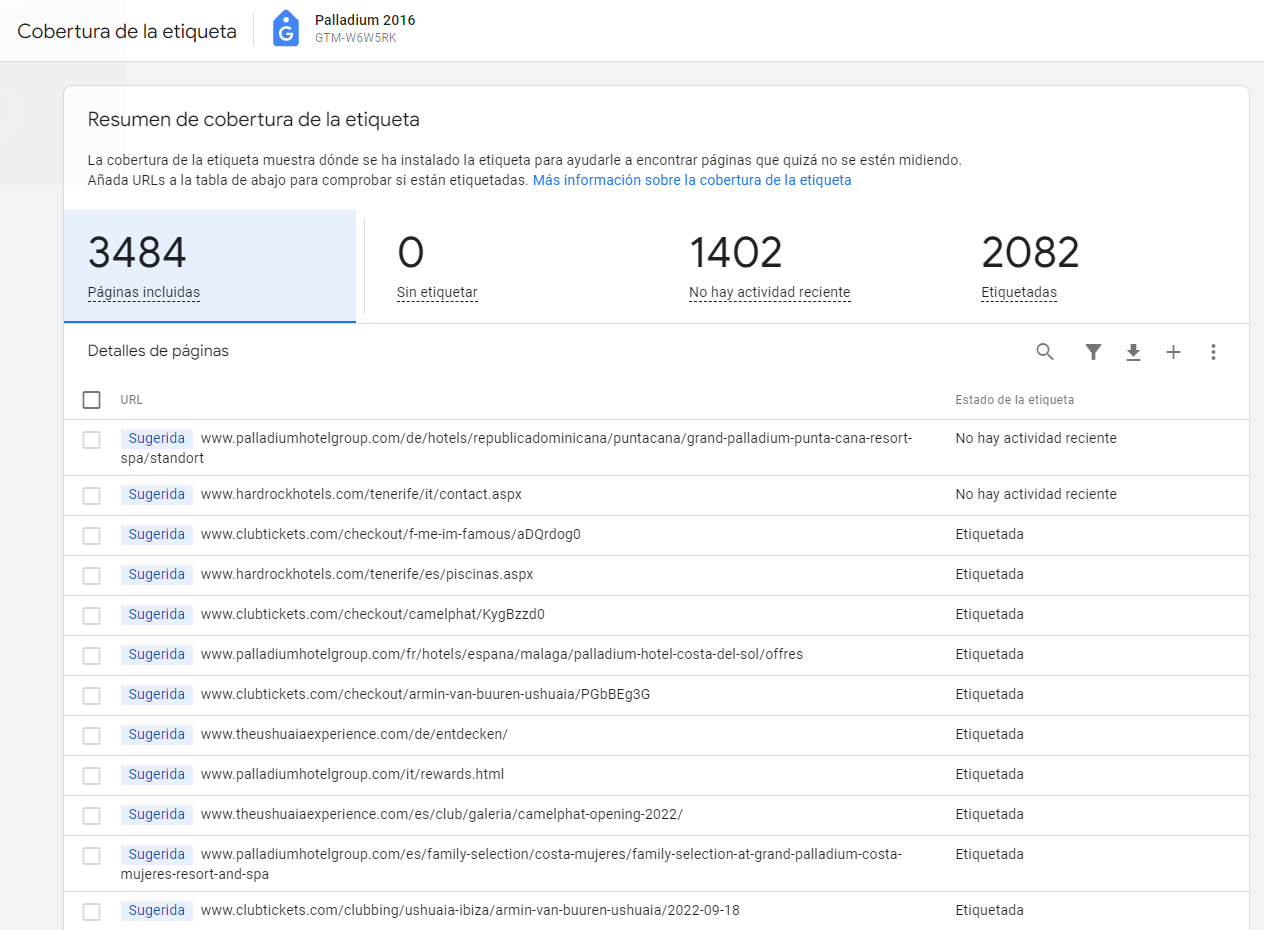
Al acceder a esta sección, se nos proporciona un listado de URLs sugeridas de nuestro site sobre las que GTM ha encontrado el tag de Google, este listado no tiene por qué incluir todas las URLs del site, son las URLs que han tenido alguna actividad, es decir, han sido consultadas por los usuarios y han enviado alguna información a GA4, es necesario aceptar estas sugerencias si queremos que se mantengan ya que se eliminarán a los 60 días.
El listado permite aceptar esas sugerencias o ignorarlas. Podríamos ignorarlas si vemos que alguna lleva un dominio que utilizamos para pruebas en los que tenemos instalado nuestro contenedor. En total se pueden mantener un total de 10.000 URLs.
El listado muestra la URL y el estado del tag en esa URL, los diferentes estados pueden ser: Etiquetada, No etiquetada, Sin actividad reciente.
Es de suponer que las URLs sugeridas están etiquetadas, puesto que se añaden al detectar el contenedor en ellas, pero pueden pasar al estado “Sin actividad reciente” si en los últimos 30 días no han cargado el contenedor, bien porque lo han perdido, bien porque no se ha accedido a esa página por ningún usuario, en esos 30 días.
El orden del listado depende del estado de la etiqueta, dejando en último lugar las que están etiquetadas, pero es posible, desde el buscador, localizar cualquier URL con facilidad.
Aumente la precisión de su analítica web
La potencia de esta funcionalidad radica en la posibilidad de añadir URLs, bien mediante un fichero CSV, o bien incluyendo la URL de forma manual, para poder validar aquellas URLs que no sabemos con seguridad si llevan el contenedor, o hacer una validación completa de todo nuestro site, aunque sea añadiendo estas URLs por partes si superan el límite de 10.000. La validación de estas nuevas URLs añadidas puede tardar hasta 24 horas.
El problema viene, según mi experiencia con clientes, en que es complicado contar con un sitemap que lleve el listado actualizado de las URLs del site o que te avisen de las nuevas páginas que se van a crear e incluir al site.