Sesgos y cómo detectarlos I
Camila Larrosa
26/09/2022
Terminamos el último artículo sobre el tema haciendo referencia al conjunto de debates que genera la reflexión en torno a la ética algorítmica y sus límites. En este texto intentaremos explorar algunas soluciones para detectar estos conflictos éticos potenciales mediante las metodologías que aplicamos desde Datarmony para intentar mitigar las posibles injusticias que se puedan producir en los algoritmos.
Empezamos con algunas definiciones. ¿Recuerdas la palabra sesgo? La relevancia que ha alcanzado esta palabra en los últimos años en el campo de la ciencia de datos se explica por el hecho de que los sesgos pueden ser de lo más imperceptibles Los sesgos acumulados en varias etapas del procesado de datos, son los mayores responsables de los daños que puede causar un uso sin supervisión de la inteligencia artificial. De forma general identificamos este tipo de daños en dos tipos: Daños de asignación y daños a la calidad del servicio.
El daño de asignación se refiere a si un modelo de inteligencia artificial extiende o retiene oportunidades, recursos o información para ciertos grupos. Por ejemplo, podemos citar el famoso caso de la herramienta COMPAS – se tarta de una herramienta utilizada por el sistema penitenciario estadounidense para la evaluación de riesgos previa al juicio – donde un informe realizado por Propublica en 2016, denunció que: «COMPAS etiquetó erróneamente a los acusados negros como futuros delincuentes en casi el doble de la tasa de acusados blancos». Es decir, aclaró que esta herramienta funciona mejor para un grupo étnico que para el otro.
El daño a la calidad del servicio, por su parte, se refiere al funcionamiento del modelo, si funciona mejor para un grupo de personas que para otro. Por ejemplo, un sistema de reconocimiento de voz puede fallar más para las mujeres y funcionar mejor para los hombres.
Otro punto que debe ser destacado es que, en el contexto de aprendizaje automático, un algoritmo se considera justo (con equidad), si no presenta sesgos. Es decir, si sus resultados son independientes de un determinado conjunto de variables que consideramos sensibles y no relacionadas con él (ej.: género, etnia, orientación sexual, etc.).
Diremos que una variable es sensible cuando no está regulada y está, en cierto modo, a merced de quien manipula los datos. En general, podemos tratar de identificarlas en términos de características sensibles y legalmente protegidas, como la etnia y el género, pero también pueden ser muy específicas del contexto de su modelo.
Priorizar la equidad en los sistemas de inteligencia artificial es un desafío social y técnico, las dos áreas acaban por ser interdependientes, y de ahí la dificultad de una respuesta simple. En Datarmony, proponemos utilizar un conjunto de herramientas de código abierto de Microsoft, llamada Fairlean, para cuantificar y mitigar las inequidades que se pueden cometer sobre un determinado grupo sensible en un modelo de aprendizaje automático.
La cuantificación de la injusticia en Fairlearn se realiza a través de métricas que miden la equidad grupal, o en otro sentido, la disparidad entre grupos, cuando existe. La herramienta se centra en dos de las principales métricas de uso común dentro del ámbito de la equidad: paridad demográfica (demographic parity) y probabilidades igualadas (equalized odds).
La paridad demográfica es la métrica que confirma si la proporción de cada subgrupo de una variable sensible recibe el resultado positivo (la salida del algoritmo) en proporciones iguales, o sea, requiere que la probabilidad de obtener un resultado sea independiente de la variable sensible. La métrica de probabilidades iguales asegura que la probabilidad de obtener un resultado positivo es independiente de la variable sensible y condicionada a la variable objetivo. Si nos basamos en el concepto de matriz de confusión, significa que la tasa de verdaderos positivos y la tasa de falsos positivos son las mismas para cada subgrupo de la variable sensible.
En cuanto a la mitigación de cualquier inequidad verificada por estas métricas, la herramienta ofrece dos opciones de algoritmos:
1) Mitigación por reducción: estos algoritmos toman un estimador de aprendizaje automático estándar de caja negra y generan un conjunto de modelos que se vuelven a entrenar con una secuencia de conjuntos de datos de entrenamiento que se han vuelto a ponderar. A continuación, los usuarios pueden elegir un modelo que les ofrezca el mejor equilibrio entre la precisión (u otra métrica de rendimiento) y la disparidad.
2) Mitigación por técnicas de posprocesamiento: el algoritmo de mitigación de injusticia toma un modelo ya entrenado y un conjunto de datos como entrada y busca ajustar una función de transformación a las salidas del modelo para satisfacer algunas restricciones de equidad (de grupo). Se añade que, estos pueden ser el único enfoque factible de mitigación de la injusticia cuando los desarrolladores no pueden influir en la capacitación del modelo, por razones prácticas, o por seguridad, o privacidad.
Y en la práctica, ¿cómo transformar algoritmos más justos con Fairlearn? Es más simple de lo que parece, y te explicamos los pasos que debes seguir, de forma esquemática, en la siguiente figura.
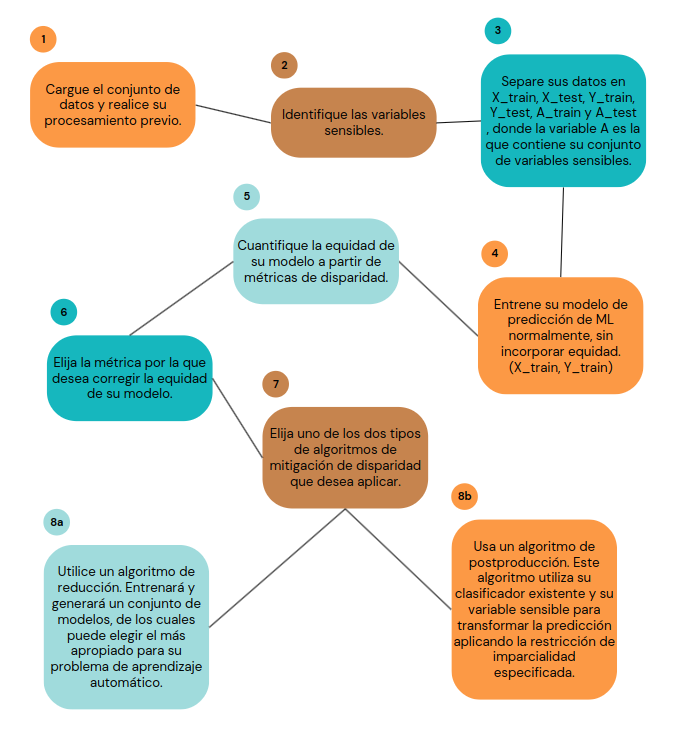
Respecto al gráfico, en el paso 3 puedes almacenar en la variable A, una o más variables sensibles. Además en el paso 6, después de verificar la existencia de una disparidad en una o más métricas, debes preguntarte (si es el segundo caso), qué métrica utilizar como definición de equidad para mitigarla.
Este paso depende mucho de la persona que desarrolla el sistema de inteligencia artificial. Pero para ayudar en esta decisión, hemos recopilado algunos puntos que puedes tener en cuenta en esta elección:
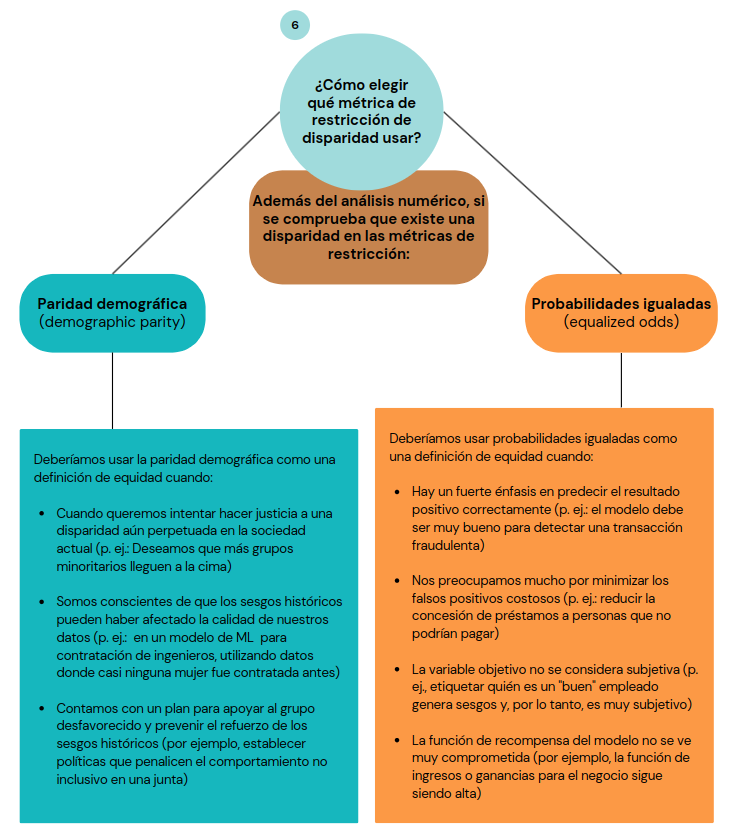
Información adaptada del artículo
Después de realizar todos estos pasos, tendrás la opción de reemplazar tu algoritmo por uno más justo. Esta decisión será tuya, y te recomiendo que la hagas basándose tanto en las tasas de disparidad de tus algoritmos (cuestión ética), como en otras de tu negocio, como la precisión mínima del modelo o incluso su coste.
Esperamos que gracias a este conjunto de propuestas estés más preparado para mitigar posibles sesgos en los algoritmos, contribuyendo a un mundo más justo, junto con Datarmony. Para asegurar tu éxito y ver estas herramientas en acción, acompañaremos este texto de otra publicación con un ejemplo real comentado y con códigos.